Data annotation allows machine learning algorithms to understand and interpret information. The annotations are labels that identify and classify data or associate different pieces of information with each other. AI algorithms use them as ground truths to adjust their weights accordingly. The labels are task-dependent and can be further categorized as an image or text annotation.
Text annotations associate meaning with textual information for ML algorithms to understand. They generate labels that allow ML algorithms to interpret the text in a human-like fashion. The process involves classifying blocks of text, tagging text elements for semantic annotation and understanding, or associating intent with conversational data. Each of these methodologies trains machine learning models for different practical use cases.
The article will discuss the following key points:
- Definition and significance of text annotation
- Text Annotation Methodologies
- Text Annotation Use Cases
About us: Viso.ai provides a robust end-to-end computer vision solution – Viso Suite. Our software helps several leading organizations start with computer vision and implement deep learning models efficiently with minimal overhead for various downstream tasks. Get a demo here.
What is Text Annotation?
The text annotation process aims to generate meaning from the text by highlighting key features such as parts of speech, semantic links, or general sentiment or intent of the document. Each annotation task labels text differently and is used for different use cases. A sentiment analysis application requires blocks of text to be classified into a sentiment category. We create sentiment annotations as follows:
“The sky is blue” – Neutral
“I am very excited about the field trip to the museum” – Happy
“I should have scored higher on the math test. It’s not fair.” – Angry
However, not all text annotations are done as above. For example, in semantic understanding, we label each part of a sentence individually, such as the subject and object.
The text documents and their associated annotations (labels) are used to train ML models for text understanding. The model learns to associate the annotations with the provided input corpus and then replicates the same association with unseen data.
Challenges for Text Annotation
The annotation process is straightforward, but it carries certain challenges. The challenges hamper the annotation quality and impact model performance. These include:
- Time-Consuming: Text corpora can be extensive, and manually labeling the entire dataset is time and resource-consuming. Certain AI-assisted annotation tools do speed up the process, but their performance varies due to the unstructured nature of the data, and human involvement is a necessity.
- Mis-classified Intent: Sentiments and intents in text documents can be difficult to decipher. Real-world datasets are filled with ambiguities like sarcasm, making annotating the user’s intent or feelings difficult.
- Text Variations: Text is a form of expression and can have the same meaning even with different structures or wording. A quality dataset must include all such variations and be annotated. Diversity increases the complexity of collected and annotated data.
Types of Text Annotation Methods
Text can be labeled using various methods, and each annotation method targets a different problem. Here are some of the most prominent text annotation methods used in the machine learning domain.
Text Classification
Text documents can be classified into different categories depending on the task at hand. The classification process associated each text document with a single label, and this association is later used to train ML algorithms. It can be further categorized as follows:
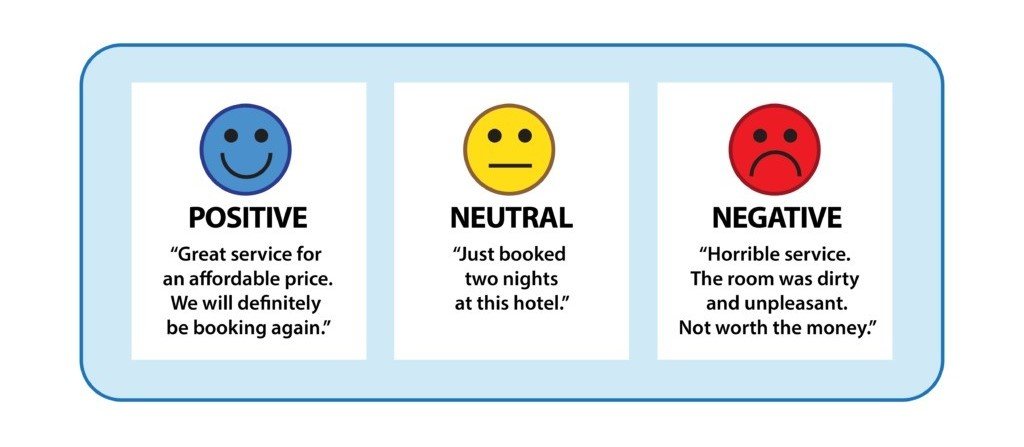
- Sentiment Annotation: Texts like customer reviews and social media posts usually express different sentiments. Such text chunks can be classified as ‘Happy,’ ‘Sad,’ ‘Angry,’ or ‘Excited.’ The annotations can be further simplified by reducing the classes to ‘Positive,’ ‘Negative,’ or ‘Neutral.’ We decide upon class granularity based on the task requirements. Sentiment annotations train sentiment classifiers used in the retail business for product review analysis.
- Topic Modelling: Text documents can also be classified according to the information they contain and the topic they represent. For example, educational texts can be classified into subjects like ‘Mathematics,’ ‘Physics,’ ‘Biology’ etc. These topics act as labels for the corpus and power topic modeling applications. Moreover, topic modeling annotations can help the chatbot understand prompt context in LLMs.
- Spam Annotation: We can annotate text collections from emails or messaging platforms as ‘Spam’ or ‘Safe.’ These annotations train spam classifiers for security applications.
Entity Tagging
Natural language text comprises various elements that give meaning to the text’s semantics. Entity tagging labels these elements into their respective classes. The tagged entities depend on the problem at hand. Understanding text semantics and its grammatical structure requires tagging parts of speed (POS), like nouns, verbs, and adjectives.
Other problems requiring generic understanding require tagging named entities like people and places and recognizing elements like addresses, contact numbers, etc.

An important distinction between classification and entity tagging is that the former assigns a single label to an entire document. In contrast, the latter assigns a label to every word in the document.
Entity Linking
Entity linkage is similar to entity tagging as it also identifies individual elements present within the text. However, it aims to link the present entity to an external knowledge base to create a wider context. For example, in the text, “Elon Musk is the founder of SpaceX”, entity linking would link ‘Elon Musk’ to the relevant information in the database to understand who the person is to better understand the text.
Intent Annotation
Chatbots recognize text commands based on the user’s intent and try to generate an appropriate response. Intent annotation classifies the text into intent categories such as request, question, command, etc. These allow chatbots to navigate the conversation and answer queries or execute actions.
Sequence-to-Sequence Annotation
Modern sequence-to-sequence models map a text sequence onto another. A popular example is text summarization models that accept a large text body as input and output a significantly compressed sequence. Another case is human language translation, where the output is a similar sequence to the input but in a different language.
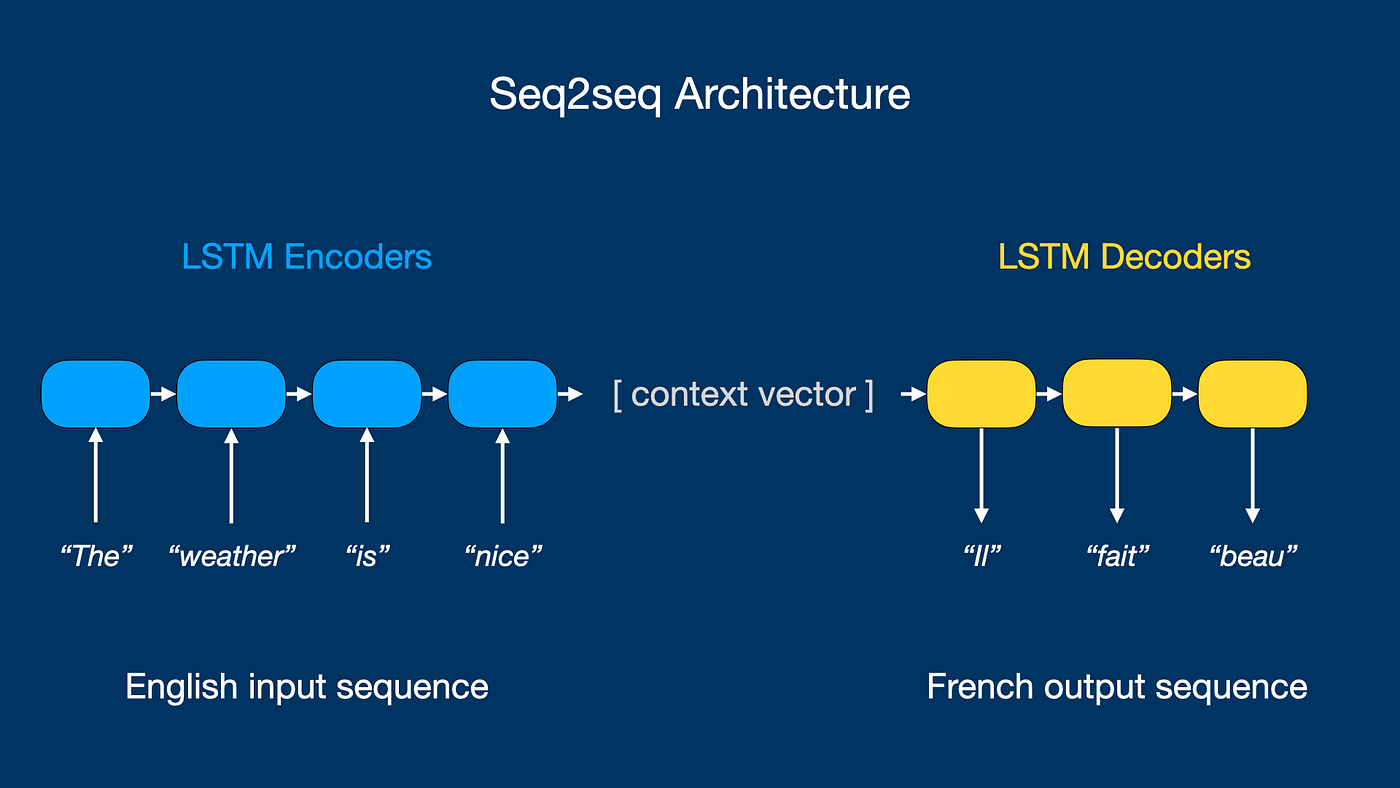
In either application, the annotations are also sequences of text that link to the original text document. For example, for the sentence ‘The weather is nice’, the annotation for a French translation model would be the following sequence ‘il fait beau’.
Applications
The text annotation techniques discussed above power various Natural Language Processing (NLP) applications. The applications have several use cases in various domains. They enable the automation of time-consuming tasks and replace manual labor with computer-operated workflows. Let’s discuss some key use cases of text annotation.
Named Entity Recognition (NER)
NER is a popular NLP application that identifies entities present within the text. The entities can include names, locations, date, and time. These entities allow computers to analyze text and execute automated workflows. For example, NER models can recognize the location, date, and time mentioned in corporate emails and set automatic reminders for a meeting.
We also use NER to extract useful entities from large bodies of text. Medical practitioners can use it to retrieve medicine and patient names from large medical files to understand what was prescribed to what patient.
Moreover, NER models also utilize context windows to understand the entity’s identity. For example, in the sentence ‘Paris is a beautiful place’, the corresponding text helps identify that ‘Paris’ is a location and not a person.
Customer Support Chatbots
Chatbots are quickly fulfilling the need for efficient customer dealing and support. Modern chatbots use a combination of classification, entity tagging, and intent identification to break down a customer query. The mentioned techniques help them understand the semantics and respond appropriately.
They can recognize entities from the text to understand which product or category a person is referring to. Furthermore, they can identify the user’s intent, whether they are inquiring about a product, requesting a refund, or registering a complaint. The intent classification helps the chatbot generate appropriate responses and execute required actions. Moreover, they also utilize sentiment analysis to recognize whether a customer is angry or upset and redirect the query to a human.
Customer Analysis
Customers often post product reviews on social media or via a designated portal from the company. Sentiment analysis allows businesses to segregate these reviews into positives and negatives without going through them manually. The negative reviews are further observed for any recurring patterns or products that require fixing. Sentiment analysis helps organizations improve product quality and customer satisfaction.
Article Segregation
Techniques like topic modeling and entity recognition segregate articles into different subjects. This is particularly prominent for news broadcasters, who segregate news articles into topics such as politics, social issues, global news, etc. Social media platforms also use the same techniques to categorize content into topics.
The categorized documents are further analyzed for hate speech or trending subjects. These analyses are used to develop new features to attract new users.
Text Annotation: Key Takeaways
Natural Language Processing (NLP) is an integral part of the AI ecosystem and has various applications powered by numerous workflows. Behind these NLP models are the text annotations that add meaning to the text and allow models to learn natural language patterns.
This article discussed text annotation in detail, covering the various techniques used and their use cases in the industry. Here’s what we learned:
- Text annotations associate labels with blocks of text.
- Annotating text is challenging due to the unstructured and ambiguous nature of the data.
- Popular text annotation techniques include:
- Sentiment Classification
- Topic Classification
- Entity Recognition
- Intent Classification
- Entity Linkage
- Classification annotations often associate a single label with an entire text document.
- Entity-level annotations associate labels with individual words.
Text annotation powers various NLP use cases like sentiment analysis, chatbots, and document analysis. Here are some additional resources to catch up on the latest AI developments:
- N-Shot Learning: Zero Shot vs. Single Shot vs. Two Shot vs. Few Shot
- Llama 2: The Next Revolution in AI-Language Models – Complete 2024 Guide
- AI Can Now Create Ultra-Realistic Images and Art from Text (2024)
- Looking into Natural Language Processing Tasks
Explore Image Annotation with Viso Suite
Modern computer vision algorithms require a vast amount of data for annotated projects. As part of the computer vision pipeline, Viso Suite offers efficient and collaborative image annotation. The toolset offers semi-automatic annotation for creating high-quality datasets for sharing and review across the team.
Viso.ai provides an end-to-end platform for creating and deploying CV applications. We offer a vast library of vision-related models with applications across various industries. We also offer data management and annotation solutions for custom training. Book a demo to learn more about Viso suite.