|
Getting your Trinity Audio player ready...
|
Natural Language Processing (NLP) makes use of Machine Learning algorithms for organising and understanding human language. NLP helps machines to not only gather text and speech but also in identifying the core meaning that it needs to respond to.
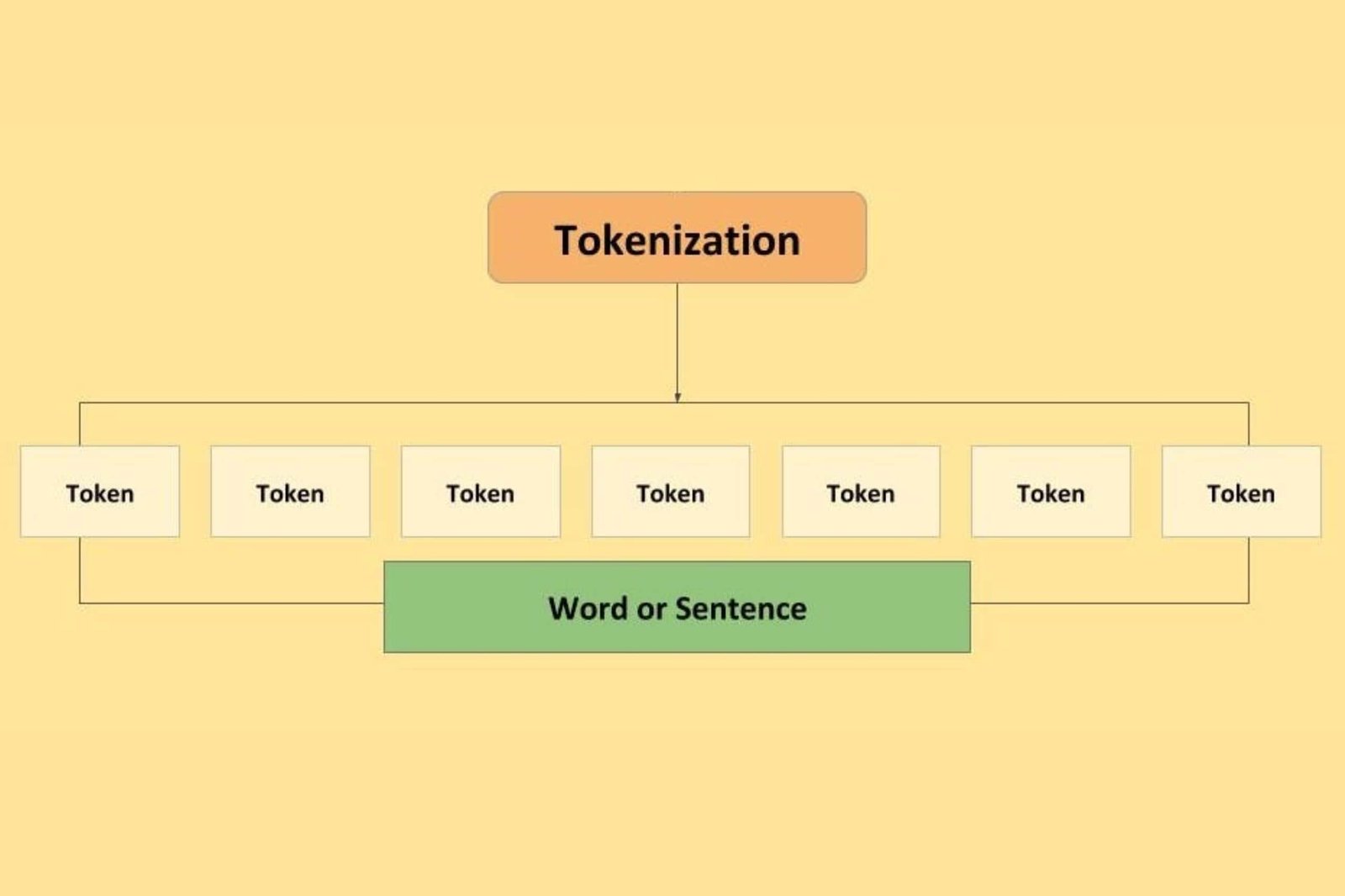
Tokenisation is one of the most crucial processes in NLP that helps in converting raw data into a useful string of data. Read the blog to know more about Tokenization in NLP.
What is Tokenization in NLP?
Tokenisation is a process in Natural Language Processing which takes into account raw data and converts them into useful data string. Tokenisation is mainly known for its use in case of cybersecurity and in the creation of NFTs while being an important part of the NLP process. In NLP, it is used for splitting paragraphs and sentences into smaller units that can easily assign meaning.
Why we need tokenization?
Tokenization is basically the first step that is undertaken in any NLP pipeline. The impact on the pipeline is extremely important. Accordingly, the tokenizer breaks unstructured data and natural language text into units of information that are considered discrete elements. The occurrences of a token within a document can be directly used as a vector that represents the document.
Types of Tokenizer in NLP:
Tokenization is a fundamental preprocessing step in Natural Language Processing (NLP) that involves breaking down text into smaller units called tokens. Tokens can be words, sentences, or sub words, depending on the specific tokenization technique used. Here are some common types of tokenization in NLP:
- Word Tokenization: Word tokenization, also known as lexical tokenization, splits text into individual words based on whitespace or punctuation. This technique treats each word as a separate token. A tokenization in NLP example can be: the sentence “I love NLP” would be tokenized into the tokens [‘I’, ‘love’, ‘NLP’].
- Sentence Tokenization: Sentence tokenization involves dividing text into individual sentences. This technique is useful when the analysis requires examining the text on a sentence-by-sentence basis. For example, the paragraph “I love NLP. It is fascinating!” would be tokenized into the tokens [‘I love NLP.’, ‘It is fascinating!’].
- Tweet Tokenizer: A Tweet Tokenizer is specifically designed to handle the unique characteristics of tweets, which are short, informal messages posted on social media platforms like Twitter. The Tweet Tokenizer takes into account the conventions and patterns commonly used in tweets, such as hashtags, mentions, emoticons, URLs, and abbreviations. It can effectively split a tweet into meaningful tokens while preserving the context and structure specific to tweets. This tokenizer is useful for tasks like sentiment analysis, topic classification, or social media analysis.
- Regex Tokenizer: Regex Tokenizer, short for Regular Expression Tokenizer, utilizes regular expressions to define patterns for tokenization. Regular expressions are powerful tools for pattern matching in text. With Regex Tokenizer, you can specify custom patterns or rules based on regular expressions to split text into tokens. This allows for flexible and precise tokenization based on specific patterns or structures present in the text. Regex Tokenizer can be useful when dealing with complex tokenization requirements or specialized domains where standard tokenization techniques may not suffice.
These are some of the commonly used tokenization techniques in NLP. The choice of tokenization method depends on the specific task, language, and requirements of the NLP application. Different tokenization techniques may be used in combination or sequentially to achieve the desired level of granularity and representation for text analysis.
Challenges of Tokenization in NLP
Tokenization in NLP comes with several challenges that can impact the accuracy and effectiveness of downstream tasks. Here are some common challenges associated with tokenization:
- Ambiguity: Ambiguity arises when a word or phrase can have multiple interpretations or meanings. Tokenization may result in different token boundaries depending on the context, which can affect the intended representation of the text. Resolving ambiguity requires understanding the surrounding context or utilizing advanced techniques such as part-of-speech tagging or named entity recognition.
- Out-of-Vocabulary (OOV) Words: OOV words are words that do not exist in the vocabulary or training data of a model. Tokenization may encounter OOV words that have not been seen before, leading to their representation as unknown tokens. Handling OOV words effectively requires techniques like subword tokenization or incorporating external resources such as word embeddings or language models.
- Contractions and Hyphenated Words: Contractions, such as “can’t” or “don’t,” and hyphenated words, like “state-of-the-art,” pose challenges for tokenization. Deciding whether to split or preserve these words as a single token depends on the context and desired representation. Incorrect tokenization can affect the meaning and interpretation of the text.
- Special Characters and Punctuation: Special characters, punctuation marks, and symbols need careful handling during tokenization. Some punctuation marks may carry contextual information or affect the meaning of adjacent words. Tokenization must consider whether to include or exclude punctuation, how to handle emoticons, URLs, or special characters in different languages.
- Languages with No Clear Word Boundaries: Some languages, such as Chinese, Japanese, or Thai, do not have clear word boundaries, making word tokenization more challenging. Tokenization techniques need to consider the morphological structure of the language and find appropriate boundaries based on contextual cues or statistical models.
- Tokenization Errors: Tokenization algorithms may occasionally make errors, splitting or merging words incorrectly. Errors can arise due to variations in writing styles, language-specific challenges, or noisy text data. These errors can impact subsequent NLP tasks, such as machine translation, sentiment analysis, or information retrieval.
- Tokenization for Domain-Specific Text: Tokenization in specialized domains, such as scientific literature or medical texts, can be challenging due to domain-specific jargon, abbreviations, or complex terminologies. Developing domain-specific tokenization rules or leveraging domain-specific resources can help address these challenges.
Addressing these challenges requires a combination of linguistic knowledge, domain expertise, and advanced NLP techniques. Tokenization algorithms need to be robust, adaptable, and capable of handling diverse language structures and contextual nuances to ensure accurate and meaningful representations of text in NLP applications.
Applications of Tokenization
Some common applications of tokenization in NLP are as follows:
- Text Classification: Tokenization plays a crucial role in text classification tasks such as sentiment analysis, spam detection, or topic categorization. By breaking down text into tokens, it enables feature extraction and representation, allowing machine learning algorithms to process and analyze the text effectively.
- Named Entity Recognition (NER): NER is a task that involves identifying and classifying named entities in text, such as person names, locations, organizations, or dates. Tokenization is a crucial step in NER as it helps identify the boundaries of named entities, making it easier to extract and label them accurately.
- Machine Translation: Tokenization is essential in machine translation systems. By breaking down sentences into tokens, it facilitates the translation process by aligning source language tokens with their corresponding translated tokens. It helps maintain the integrity of the sentence structure and ensures accurate translations.
- Part-of-Speech (POS) Tagging: POS tagging involves assigning grammatical labels to individual words in a sentence, such as noun, verb, adjective, etc. Tokenization is a prerequisite for POS tagging, as it segments the text into words, enabling the assignment of appropriate POS tags to each word.
- Sentiment Analysis: Sentiment analysis aims to determine the sentiment expressed in a piece of text, whether it is positive, negative, or neutral. Tokenization allows for the extraction of sentiment-bearing words or phrases, which are crucial for sentiment analysis algorithms to analyze and classify the sentiment expressed in the text.
Conclusion
From the above blog, you learn about the concept and application of Tokenization in NLP which helps you I breaking raw texts into smaller chunks called tokens. You now understand the importance of Tokenization and the different types and challenges of tokenization in NLP. The applications of tokenization in NLP can be seen to be spread over quite different domains in the field of Data Science from Machine Translation to sentiment analysis.
Author
-

Written by:
Asmita Kar



