Logo:
Logo:  Areas Served:
Areas Served: Inside Ghostbuster: Berkeley University’s New Method for Detecting AI-Generated Content
Last Updated on November 17, 2023 by Editorial Team
Author(s): Jesus Rodriguez
Originally published on Towards AI.
I recently started an AI-focused educational newsletter, that already has over 160,000 subscribers. TheSequence is a no-BS (meaning no hype, no news, etc) ML-oriented newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers, and concepts. Please give it a try by subscribing below:
TheSequence U+007C Jesus Rodriguez U+007C Substack
The best source to stay up-to-date with the developments in the machine learning, artificial intelligence, and data…
thesequence.substack.com
The rapid evolution of large language models(LLMs) has created new challenges in terms of differentiating between human and AI-generated content. Recently, we have seen all sorts of solutions emerge to try to tackle this challenge, but the number of false positives is quite concerning. Recently, Berkeley AI Research(BAIR) published a new paper introducing a technique for identifying AI-generated content.
Ghostbuster, as presented in a recent research paper, emerges as a formidable solution for the identification of AI-generated text. Its operational framework revolves around the meticulous calculation of the likelihood of generating each token within a document under the scrutiny of various weaker language models. Subsequently, Ghostbuster employs a fusion of functions derived from these token probabilities to serve as inputs for a conclusive classifier.
A notable attribute of Ghostbuster is its model-agnostic nature. It operates without any prior knowledge of the specific model responsible for document generation or the probability associated with that model’s output. This inherent quality imbues Ghostbuster with a unique utility in detecting text that may have been generated by an unknown or black-box model, a scenario commonly encountered with popular commercial models like ChatGPT and Claude, where probabilities remain undisclosed.

Inside Ghostbuster
Ghostbuster’s inner workings unfold through a meticulously designed three-stage training process. Each stage contributes to the system’s ability to discern AI-generated text effectively.
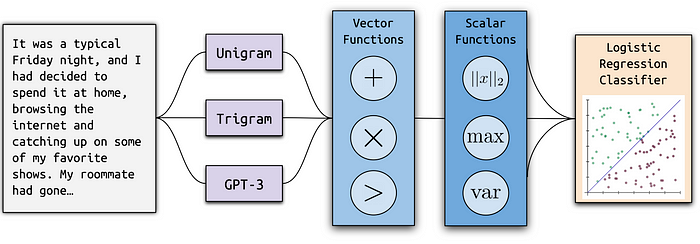
- Computing Probabilities: The initial phase involves transforming each document into a series of vectors. This transformation is achieved by assessing the likelihood of generating individual words within the document. Ghostbuster accomplishes this by consulting a range of weaker language models, including a unigram model, a trigram model, and two non-instruction-tuned GPT-3 models, ada and davinci.
- Selecting Features: The second stage hinges on a structured feature selection procedure. It operates by establishing a set of vector and scalar operations intended to combine the probabilities calculated in the previous step. This procedure then systematically explores various combinations of these operations through forward feature selection, consistently incorporating the most beneficial features.
- Classifier Training: The final stage culminates in the training of a linear classifier. This classifier is built using the most promising probability-based features identified during the feature selection process. Additionally, certain manually selected features are integrated into the model to enhance its performance.
In practice, Ghostbuster initiates its analysis by subjecting paired human-authored and AI-generated documents to a battery of weaker language models. This array of models spans from rudimentary unigram models to the more advanced non-instruction-tuned GPT-3 model, davinci. Ghostbuster then harnesses the word probabilities yielded by these models to explore a multidimensional space of vector and scalar functions. This exploration is geared towards synthesizing these probabilities into a concise set of features.
The final step in the Ghostbuster process involves feeding these extracted features into a linear classifier, as expounded in Section 4 of the methodology. The result is a model that consistently achieves an impressive F1 score of 99.0 in in-domain classification. Notably, Ghostbuster outperforms both DetectGPT and GPTZero by an average margin of 23.7 F1, underscoring its effectiveness in identifying AI-generated text across various contexts and scenarios.
The Results
Ghostbuster’s commitment to robust generalization is a pivotal aspect of its design. To ensure its efficacy across diverse text generation scenarios, Ghostbuster underwent extensive evaluation. This evaluation encompassed a comprehensive exploration of various factors, including different domains, language models, and prompts. The evaluation process was facilitated by the incorporation of newly collected datasets comprising essays, news articles, stories, and more.
When trained and tested on the same domain, Ghostbuster achieved 99.0 F1 across all three datasets, outperforming GPTZero by a margin of 5.9 F1 and DetectGPT by 41.6 F1. Out of domain, Ghostbuster achieved 97.0 F1 averaged across all conditions, outperforming DetectGPT by 39.6 F1 and GPTZero by 7.5 F1. Our RoBERTa baseline achieved 98.1 F1 when evaluated in-domain on all datasets, but its generalization performance was inconsistent. Ghostbuster outperformed the RoBERTa baseline on all domains except creative writing out-of-domain and had much better out-of-domain performance than RoBERTa on average (13.8 F1 margin).

Ghostbuster is one of the most creative methods ever created for the detection of AI-generated content. The method seems generic enough to be applicable across different types of LLMs. Certainly, would like to see implementations of Ghostbuster applied to different detection tools.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts