
TikTok's Recommendation Engine Explained: Monolith
TikTok's Recommendation Engine Explained: Monolith
LeapFrogAI, ggml, Video2DataSet, Otter and new models from Stability AI

Articles
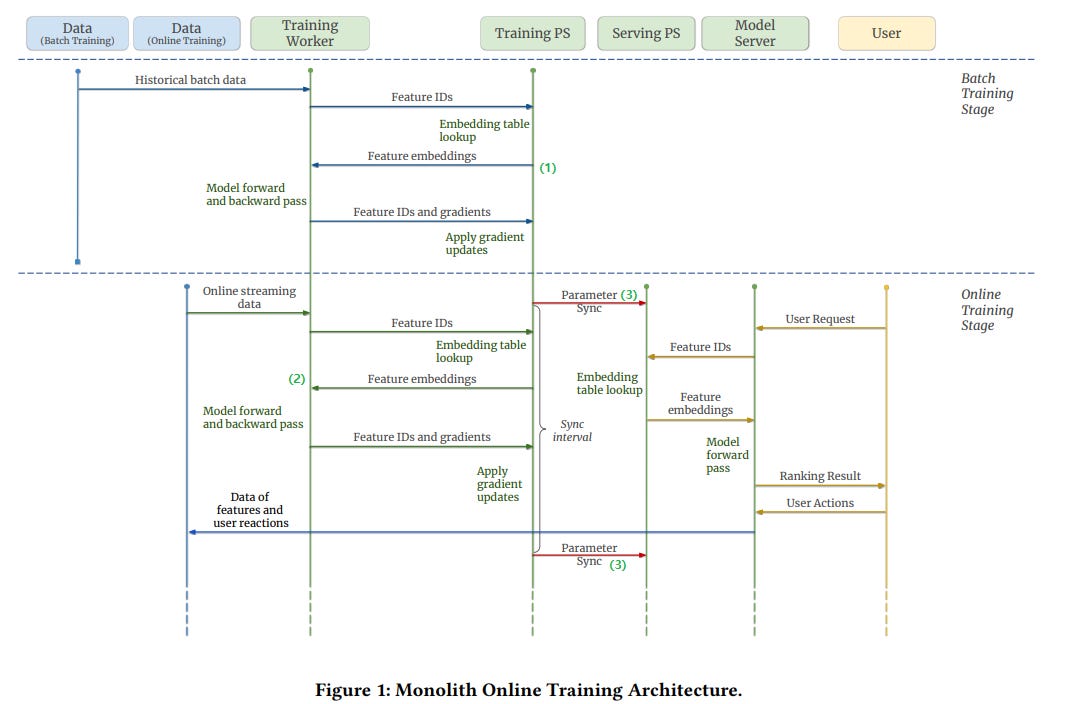
Haneul Kim wrote a blog post on the Monolith paper where the paper talks about recommendation systems of Monolith which is the main recommender system that powers TikTok.
The post provides an overview of the architecture and design of TikTok's recommender system. The system is designed to be real-time, meaning that it can generate recommendations for users in a matter of milliseconds. This is achieved by using a number of techniques, including:
Sparsity-aware factorization machines: These models are designed to handle the sparsity of real-world recommender system data and they found sparse signals to be the most useful features.
Online learning: The system uses online learning to continuously update its models based on new user data.
Caching: The system uses caching to store frequently accessed data, which helps to improve performance.
The paper also discusses some of the challenges of building a real-time recommender system, such as the need to handle large volumes of data and the need to keep up with the ever-changing nature of user preferences.

Laion published a blog post on a tool they call Video2Dataset. Within only two years large foundational models like CLIP, Stable Diffusion, and Flamingo have fundamentally transformed multimodal deep learning. Because of such models and their impressive capabilities to either create stunning, high-resolution imagery or to solve complex downstream tasks, joint text-image modeling has emerged from a niche application to one of the (or maybe the) most relevant topics in today’s AI landscape. Remarkably, all these models, despite addressing very different tasks and being very different in design, share three fundamental properties as the main drivers behind their strong performance: A simple and stable objective function during (pre-)training, a well-investigated scalable model architecture, and - probably most importantly - a large diverse dataset.
As of 2023, multimodal deep learning is still heavily focusing on text-image modeling, while other modalities such as video (and audio) are only sparsely investigated. Since the algorithms to train the above models are usually modality agnostic, one might wonder why there aren’t strong foundational models for these additional modalities. The reason for this is – plain and simple – the lacking availability of large scale, annotated datasets. As opposed to image modeling, where there are established datasets for scaling such as LAION-5B, DataComp, and COYO-700M and scalable tools as img2dataset, this lack of clean data hinders research and development of large multimodal models especially for the video domain.
They introduce video2dataset, an open-source tool designed to curate video and audio datasets efficiently and at scale. It's flexible, extendable, offers a wide variety of transformations, and has been successfully tested on various large video datasets. All these examples are available in the repository, along with instructions for replicating our process.
The code is in GitHub.
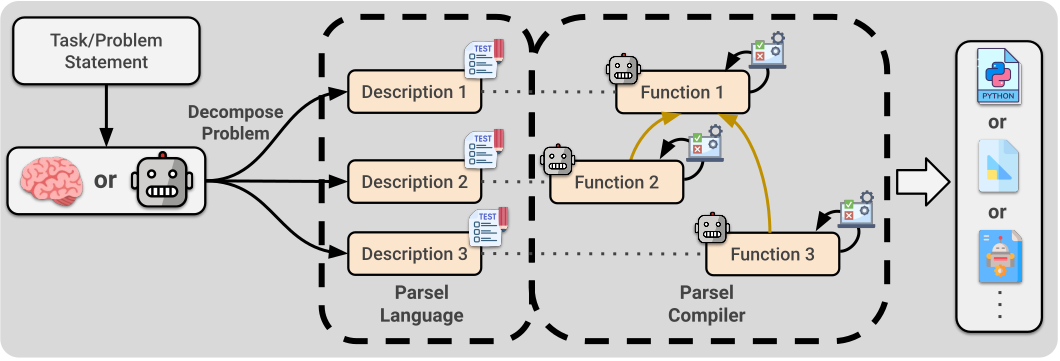
Despite recent success in large language model (LLM) reasoning, LLMs struggle with hierarchical multi-step reasoning tasks like generating complex programs. For these tasks, humans often start with a high-level algorithmic design and implement each part gradually. Parsel is a new framework enabling automatic implementation and validation of complex algorithms with code LLMs, taking hierarchical function descriptions in natural language as input. Stanford researchers found that LLMs generating Parsel solve more competition-level problems in the APPS dataset, resulting in pass rates that are over 75% higher than prior results from directly sampling AlphaCode and Codex, while often using a smaller sample budget. LLM-generated robotic plans using Parsel as an intermediate language are more than twice as likely to be considered accurate than directly generated plans.
Libraries
VisText is a benchmark dataset of over 12,000 charts and semantically rich captions! In the VisText dataset, each chart is represented as its rasterized image, scene graph specification, and underlying datatable. Each chart is paired with a synthetic L1 caption that describes the chart's elemental and ecoded properties and a human-generated L2/L3 caption that describes trends and statistics about the chart.
Danswer allows you to ask natural language questions against internal documents and get back reliable answers backed by quotes and references from the source material so that you can always trust what you get back. You can connect to a number of common tools such as Slack, GitHub, Confluence, amongst others.
Features 💃
Direct QA powered by Generative AI models with answers backed by quotes and source links.
Intelligent Document Retrieval (Semantic Search/Reranking) using the latest LLMs.
An AI Helper backed by a custom Deep Learning model to interpret user intent.
User authentication and document level access management.
Connectors to Slack, GitHub, GoogleDrive, Confluence, local files, and web scraping, with more to come.
Management Dashboard to manage connectors and set up features such as live update fetching.
One line Docker Compose (or Kubernetes) deployment to host Danswer anywhere.
The code is in GitHub.
LeapfrogAI is designed to provide AI-as-a-service in egress limited environments. This project aims to bridge the gap between resource-constrained environments and the growing demand for sophisticated AI solutions, by enabling the hosting of APIs that provide AI-related services.
Our services include vector databases, completions with models like Large Language Models (LLMs), and the creation of embeddings. These AI capabilities can be easily accessed and integrated with your existing infrastructure, ensuring the power of AI can be harnessed irrespective of your environment's limitations.
Why Host Your Own LLM?
Large Language Models (LLMs) are a powerful resource for AI-driven decision making, content generation, and more. However, the use of cloud-based LLMs can introduce limitations such as:
Data Privacy and Security: Sending sensitive information to a third-party service may not be suitable or permissible for all types of data or organizations. By hosting your own LLM, you retain full control over your data.
Cost: Pay-as-you-go AI services can become expensive, especially when large volumes of data are involved. Running your own LLM can often be a more cost-effective solution in the long run.
Customization and Control: By hosting your own LLM, you have the ability to customize the model's parameters, training data, and more, tailoring the AI to your specific needs.
Latency: If your application requires real-time or near-real-time responses, hosting the model locally can significantly reduce latency compared to making a round trip to a remote API.
Milvus is an open-source vector database built to power embedding similarity search and AI applications. Milvus makes unstructured data search more accessible, and provides a consistent user experience regardless of the deployment environment.
Milvus 2.0 is a cloud-native vector database with storage and computation separated by design. All components in this refactored version of Milvus are stateless to enhance elasticity and flexibility. For more architecture details, see Milvus Architecture Overview.
ggml is another tensor library for machine learning. Its roadmap and manifesto are available.
Features
Written in C
16-bit float support
Integer quantization support (4-bit, 5-bit, 8-bit, etc.)
Automatic differentiation
ADAM and L-BFGS optimizers
Optimized for Apple Silicon
On x86 architectures utilizes AVX / AVX2 intrinsics
On ppc64 architectures utilizes VSX intrinsics
No third-party dependencies
Zero memory allocations during runtime
🦦 Otter, a multi-modal model based on OpenFlamingo (open-sourced version of DeepMind's Flamingo), trained on MIMIC-IT and showcasing improved instruction-following and in-context learning ability.

Stability AI are releasing two new diffusion models for research purposes:
SDXL-base-0.9: The base model was trained on a variety of aspect ratios on images with resolution 1024^2. The base model uses OpenCLIP-ViT/G and CLIP-ViT/L for text encoding whereas the refiner model only uses the OpenCLIP model.SDXL-refiner-0.9: The refiner has been trained to denoise small noise levels of high quality data and as such is not expected to work as a text-to-image model; instead, it should only be used as an image-to-image model.
Below the Fold
VS Code gets a lot of nice CoPilot features
Marc Andreessen wrote a nice piece on why AI is a net positive and will still be in future.
The piece argues that AI has the potential to solve many of the world's most pressing problems, such as poverty, disease, and climate change. He believes that AI will make everything we care about better, from our health to our economy to our relationships.
While mentioning these, he also acknowledges the possibility of job displacement or even existential catastrophe. However, he argues that these risks are manageable and that the potential benefits of AI far outweigh the risks.
He concludes by calling for a more open and optimistic approach to AI development. He believes that we should embrace AI as a tool for good and that we should not let fear or misunderstanding prevent us from realizing its full potential.