
 Logo:
Logo:  Areas Served:
Areas Served: 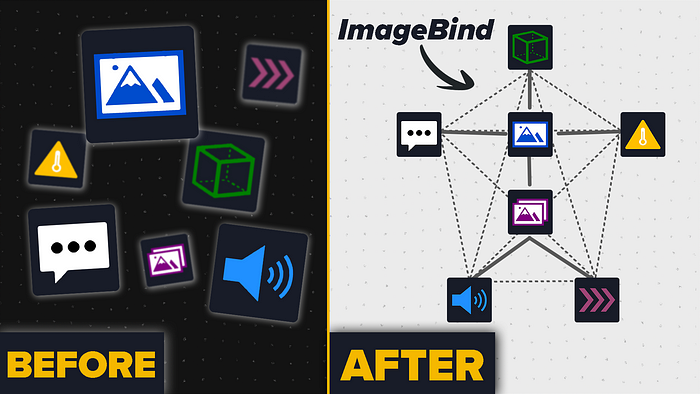
Is This Real Multi-Modal Learning? — ImageBind explained
Last Updated on November 7, 2023 by Editorial Team
Author(s): Boris Meinardus
Originally published on Towards AI.
Image to text or audio to text, that’s the multi-modal learning from last year! ImageBind [1] by Meta AI. Now that’s real multi-modal learning!
ImageBind combines multiple modalities into one shared embedding space. This means we can do cross-modal retrieval, i.e. we can input an audio sequence, e.g., some crackling fire, and retrieve an image of a crackling fire. Or we can even combine two different modalities, like an image of a bird, and the sound of waves, to retrieve an image of the same bird in the sea. And what about upgrading DALLE-2 to use audio as an input instead… Read the full blog for free on Medium.
Join thousands of data leaders on the AI newsletter. Join over 80,000 subscribers and keep up to date with the latest developments in AI. From research to projects and ideas. If you are building an AI startup, an AI-related product, or a service, we invite you to consider becoming a sponsor.
Published via Towards AI
Related posts
Popular posts

 for 2021")



Updates

Recent Posts

