Open-source datasets for Conversational AI: advantages and limitations
Open-source datasets are a valuable resource for developers and researchers working on conversational AI. These datasets provide large amounts of data that can be used to train machine learning models, allowing developers to create conversational AI systems that are able to understand and respond to natural language input.
There are many open-source datasets available, but some of the best for conversational AI include the Cornell Movie Dialogs Corpus, the Ubuntu Dialogue Corpus, and the OpenSubtitles Corpus. These datasets offer a wealth of data and are widely used in the development of conversational AI systems. However, there are also limitations to using open-source data for machine learning, which we will explore below.
Here is a list of the top 8 freely available resources for Conversational AI:
- The Cornell Movie Dialogs Corpus is a collection of more than 220,000 lines of movie character dialogue. It includes conversations from more than 600 movies and full metadata for movies (such as genre, release year, IMDB rating) and characters.
- The Ubuntu Dialogue Corpus is a large dataset of human-human conversations from the Ubuntu chat logs. The full dataset contains 930,000 dialogues and over 100,000,000 words, spread out over 26 million turns.
- The OpenSubtitles Corpus is a collection of more than 1.5 million movie and TV subtitles. It’s a useful resource for training conversational AI systems, as it provides a large amount of natural language data in 62 languages.
- The Microsoft Research Social Media Conversation Corpus is a dataset of more than 12,000 tweets extracted from Twitter logs. It’s a valuable resource for training conversational AI systems, as it provides a large amount of natural language data from social media platforms.
- The Microsoft Research Social Media Conversation Corpus is a dataset of more than 12,000 tweets extracted from Twitter logs. It’s a valuable resource for training conversational AI systems, as it provides a large amount of natural language data from social media platforms.
- The Reddit Comments Corpus is a dataset of more than 1.7 billion comments from the Reddit social media website. It’s useful because of the colloquial language used on Reddit, the accurate division of topics, and the rich metadata it offers.
- The Twitter US Airline Sentiment Corpus is a dataset of more than 14,000 tweets from US airline customers. It provides a large amount of natural language data from customer service interactions and is tagged with positive, neutral, or negative sentiment.
- The Common Crawl Corpus is a dataset of more than 3 billion web pages collected over 12 years of Common Crawl’s web indexing. The corpus contains raw web page data, metadata extracts, and text extracts.
- The Enron Email Corpus is a collection of more than 600,000 emails from the Enron Corporation. It contains data from about 150 users—mostly senior management—organized into folders.
While open-source datasets can be a useful resource for training conversational AI systems, they have their limitations. The data may not always be high quality, and it may not be representative of the specific domain or use case that the model is being trained for. Additionally, open-source datasets may not be as diverse or well-balanced as commercial datasets, which can affect the performance of the trained model.
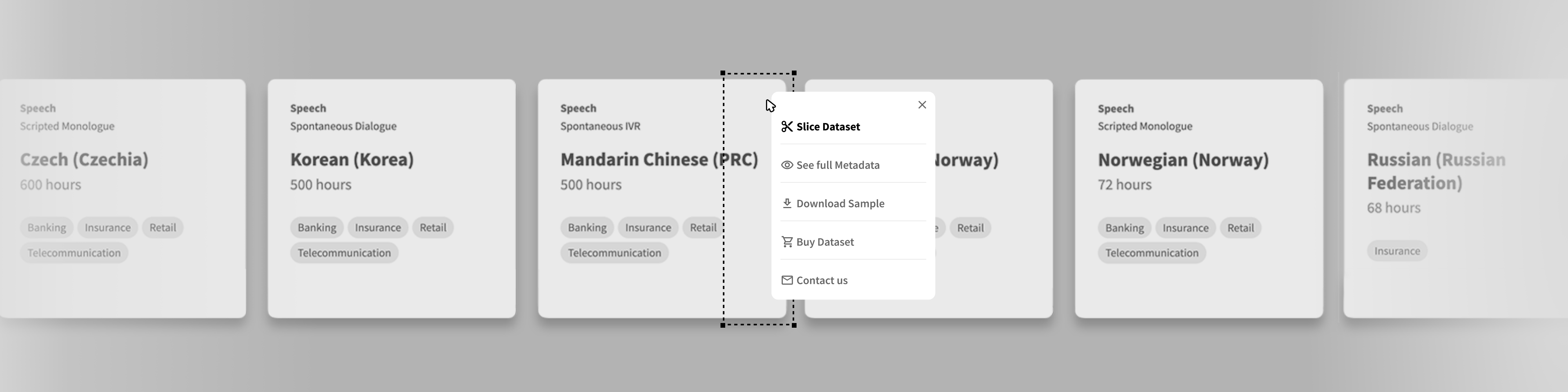
At Defined.ai, we offer a data marketplace with high-quality, commercial datasets that are carefully designed and curated to meet the specific needs of developers and researchers working on conversational AI. Our datasets are representative of real-world domains and use cases and are meticulously balanced and diverse to ensure the best possible performance of the models trained on them.
Additionally, the use of open-source datasets for commercial purposes can be challenging due to licensing. Many open-source datasets exist under a variety of open-source licenses, such as the Creative Commons license, which do not allow for commercial use. This means that companies looking to use open-source datasets for commercial purposes must first obtain permission from the creators of the dataset or find a dataset that is licensed specifically for commercial use. This can be a time-consuming and potentially costly process.
In addition to the quality and representativeness of the data, it is also important to consider the ethical implications of sourcing data for training conversational AI systems. This includes ensuring that the data was collected with the consent of the people providing the data, and that it is used in a transparent manner that’s fair to these contributors.
It’s also important to consider data security, and to ensure that the data is being handled in a way that protects the privacy of the individuals who have contributed the data. At Defined.ai, we take these ethical considerations seriously, and our Data Marketplace includes only high-quality, commercial datasets that have been collected with user consent and are handled with the utmost care and attention to data security.
If you’re looking for data to train or refine your conversational AI systems, visit Defined.ai to explore our carefully curated Data Marketplace.