A Detailed Guide on SQL Query Optimization
Introduction
SQL Query optimization is defined as the iterative process of enhancing a query’s performance in execution time, disk accesses, and other cost-measuring criteria. Data is an integral part of any application. Access to the data should be as fast as possible to enhance the user experience while using the application.
It is a very critical task. Even slight changes in SQL queries can improve performance drastically. There is no step-by-step guide for the same. In turn, we must use general guidelines for writing queries and which operators to use. Then, check for execution plans, find out which part of the query takes the most time, and rewrite that part in another way.
This article was published as a part of the Data Science Blogathon.
Table of contents
What is SQL?
SQL (Structured Query Language) is a standard language for accessing, storing, creating, and deleting databases and performing all other data-related operations. There are four types of language in SQL:
- DDL (Data Definition Language): This includes commands for creating and altering the database schema, such as CREATE, DROP, ALTER, and TRUNCATE.
- DML (Data Manipulation Language): This includes commands for updating the data in the database. It alters the relation instance, such as SELECT, UPDATE, INSERT, and DELETE.
- DCL (Data Control Language): This includes commands for access to the database, such as GRANT and REVOKE.
- TCL (Transaction Control Language): This includes the commands used to manage transactions in the database, such as COMMIT and ROLLBACK.
.jpg)
Before going toward the main topic of SQL Query optimization, let us first understand the actual processing of the query:
What is Query Processing?
Query processing is the group of phases associated with extracting data from the database. It includes converting queries written in a high-level language such as SQL into a form that the physical-level implementation of the database can understand, SQL query optimization techniques, and the original evaluation of the query.
Major Steps in Query Processing
There are three major steps involved in query processing:
.jpg)
1. Parser and translator: The first step in query processing is parsing and translation. A parser, just like a parser in compilers, checks the syntax of the query to see whether the relations mentioned are present in the database. A high-level query language such as SQL is suitable for human use. However, it is unsuitable for system internal representation. Therefore, translation is required. The internal representation can be an extended form of relational algebra.
2. Optimization: An SQL query can be written in many ways. Its optimization also depends on how the data is stored in the file organization. A Query can also have different corresponding relational algebra expressions.
.jpg)
So, the above query can be written in the two forms of relational algebra. So it depends on the implementation of the file system which one is better.
3. Execution plan: A systematic step-by-step execution of primitive operations for fetching database data is called a query evaluation plan. Different evaluation plans for a particular query have different query costs. The cost may include the number of disk accesses, CPU time for executing the query, and communication time in the case of distributed databases.
What is a Query Optimization?
Query optimization is enhancing the performance of a database query by modifying the query’s execution plan without altering its end result. The main goal is to reduce the time and resources required to retrieve the requested data from the database. Query optimization is crucial for ensuring efficient database operations, especially as the size of databases and the complexity of queries increase.
How Does Query Optimization Work?
Query optimization involves several steps and techniques that a database management system (DBMS) uses to determine the most efficient query execution. Here’s a detailed look at how this process works:
- Parsing: When a query is submitted, the DBMS parses it to check for syntax errors and understand the query structure.
- Translation: The parsed query is then translated into an internal representation, often an abstract syntax tree (AST) or a similar data structure.
- Logical Plan Generation: The DBMS generates a logical query plan, a high-level description of the operations required to execute the query. This plan includes operations like joins, selections, and projections but doesn’t consider the physical aspects of data storage.
- Logical Optimization: The logical query plan is optimized using various rules and transformations. This phase may involve predicate pushdown, query rewriting and eliminating redundancies.
- Physical Plan Generation: The optimized logical plan is converted into one or more physical query plans. Each physical plan specifies the methods and algorithms for data access and manipulation, such as index usage, joining algorithms, and access paths.
- Cost Estimation: The DBMS estimates the cost of each physical plan using a cost model that considers factors like I/O operations, CPU usage, and memory usage. The cost estimation involves:
- Statistics Analysis: Using statistics about the data (e.g., table size, index cardinality, data distribution) to predict the costs.
- Heuristics: Applying heuristic rules based on typical database performance characteristics.
- Plan Selection: The DBMS selects the physical plan with the lowest estimated cost. This plan is considered the optimal execution plan for the query.
- Execution: The selected execution plan is executed by the DBMS. During execution, the DBMS may also perform run-time optimizations, such as dynamic memory allocation and adaptive query processing.
Techniques and Tools For Query Optimization
Several techniques and tools are employed in query optimization:
- Heuristics-Based Optimization: Relies on predefined rules and patterns to transform and optimize queries. It is fast but may not always produce the best possible plan.
- Cost-Based Optimization: Uses a detailed cost model and database statistics to estimate and compare the costs of different execution plans. It tends to be more accurate but computationally intensive.
- Materialized Views: Pre-computed views that store query results and can be reused to speed up query processing.
- Query Hints: Directives provided by users to influence the optimizer’s choices, such as forcing the use of a specific index or join method.
- Adaptive Query Processing: Dynamically adjusts the query execution plan based on actual run-time conditions and performance metrics.
Also Read: Alibaba’s LLM-R2: Revolutionizing SQL Query Efficiency
Purpose of SQL Query Optimization
The major purposes of SQL Query optimization are:
1. Reduce Response Time: The major goal is to enhance performance by reducing the response time. The time difference between users requesting data and getting responses should be minimized for a better user experience.
2. Reduced CPU execution time: The CPU execution time of a query must be reduced so that faster results can be obtained.
3. Improved Throughput: The number of resources to be accessed to fetch all necessary data should be minimized. The number of rows to be fetched in a particular query should be in the most efficient manner such that the least resources are used.
Database for the Tutorial
This tutorial will use the AdventureWorks database to show various commands and their optimized solutions. You can download the database from here.
AdventureWorks database is a sample database provided by Microsoft SQL Server. This is a standard database showing day-to-day transaction processing for a business. Scenarios include sales, customer management, product management, and human resources.
For more information on the tables and relationships of the database, you can visit this link.
Metrics for Analyzing Query Performance for SQL Query Optimization
There are several metrics for calculating the cost of the query in terms of space, time, CPU utilization, and other resources:
1. Execution Time:
The most important metric to analyze the query performance is the execution time of the query. Execution time/Query duration is when the query returns the rows from the database. We can find the query duration using the following commands:
SET STATISTICS TIME ON SELECT * FROM SalesLT.Customer;
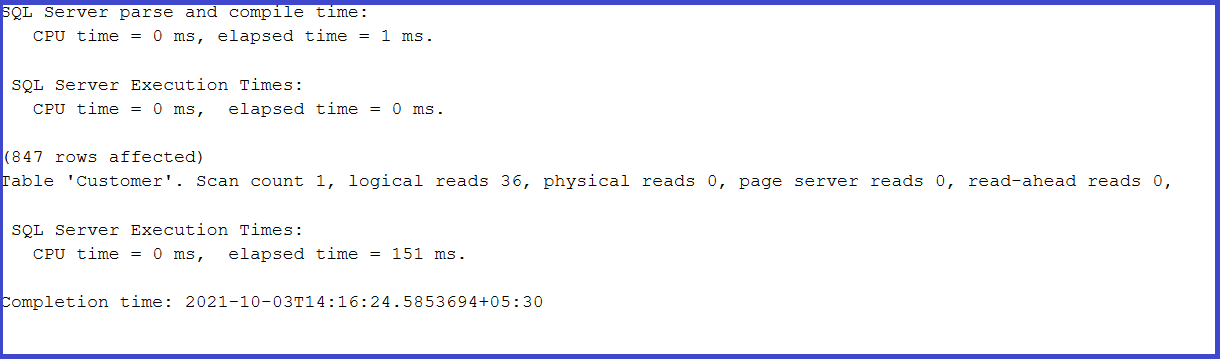
By using STATISTICS TIME ON, we can see the parse time, compile-time, execution time, and completion time of the query.
Parse and Compile Time: The time taken to parse and compile the query to check the syntax of the query is termed Parse and Compile time.
Execution Time: The query’s CPU time to fetch the data is termed Execution time.
Completion time: The exact time the query returned the result is termed Completion time.
By analyzing these times, we can get a clear picture of whether the query is performing up to the mark or not.
2. Statistics IO:
IO is the major time spent accessing the memory buffers for reading operations in case of query. It provides insights into the latency and other bottlenecks when executing the query. By setting STATISTICS IO ON, we get the number of physical and logical reads performed to execute the query.

Logical reads: Number of reads that were performed from the buffer cache.
Physical reads: The number of reads that were performed from the storage device because they were not available in the cache.
3. Execution Plan:
An execution plan is a detailed step-by-step processing plan the optimizer uses to fetch the rows. It can be enabled in the database using the following procedure. An execution plan helps us analyze the major phases in a query’s execution. We can also determine which part of the execution takes more time and optimize that sub-part.
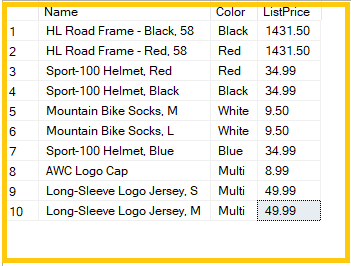
SELECT p.Name, Color, ListPrice FROM SalesLT.Product p INNER JOIN SalesLT.ProductCategory pc ON P.ProductCategoryID = pc.ProductCategoryID;

As we can see above, the execution plan shows which tables were accessed and what index scans were performed to fetch the data. If joins are present, it shows how these tables were merged.
Further, we can see a more detailed analysis of each sub-operation performed during query execution. Let us see the analysis of the index scan:
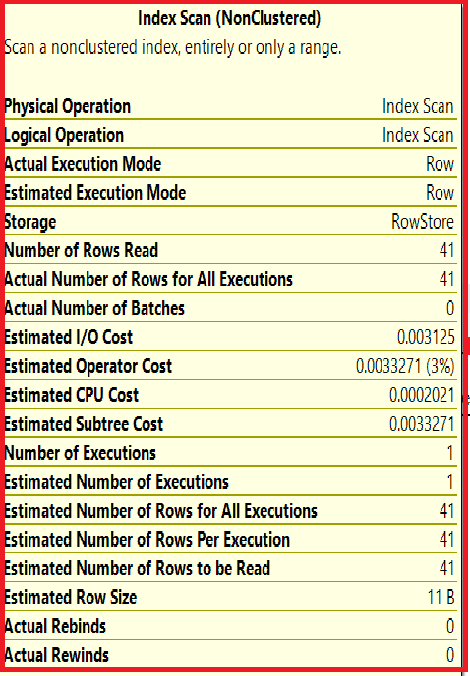
As we see above, we can get the values of the number of rows read, the actual number of batches, the estimated operator cost, the estimated CPU cost, the estimated subtree cost, the number of executions, and actual rebinds. This gives us a detailed overview of the cost involved in query execution.
SQL Query Optimization Techniques
Till now, we have seen how a query is executed and different measures to analyze the query performance. Now, we will learn the techniques to optimize the query performance in SQL. There are some useful practices to reduce the cost. However, the process of optimization is iterative. One needs to write the query, check query performance using io statistics or execution plan, and optimize it. This cycle needs to be followed iteratively for query optimization. The SQL Server finds the optimal and minimal plan to execute the query.
Indexing
An index is a data structure that provides quick access to the table based on a search key. It helps minimize the disk access required to fetch the rows from the database. An indexing operation can be a scan or a seek. An index scan traverses the entire index for matching criteria, whereas an index seeks filter rows on a matching filter.
For example,
SELECT p.Name, Color, ListPrice FROM SalesLT.Product p INNER JOIN SalesLT.ProductCategory pc ON P.ProductCategoryID = pc.ProductCategoryID INNER JOIN SalesLT.SalesOrderDetail sod ON p.ProductID = sod.ProductID WHERE p.ProductID>1
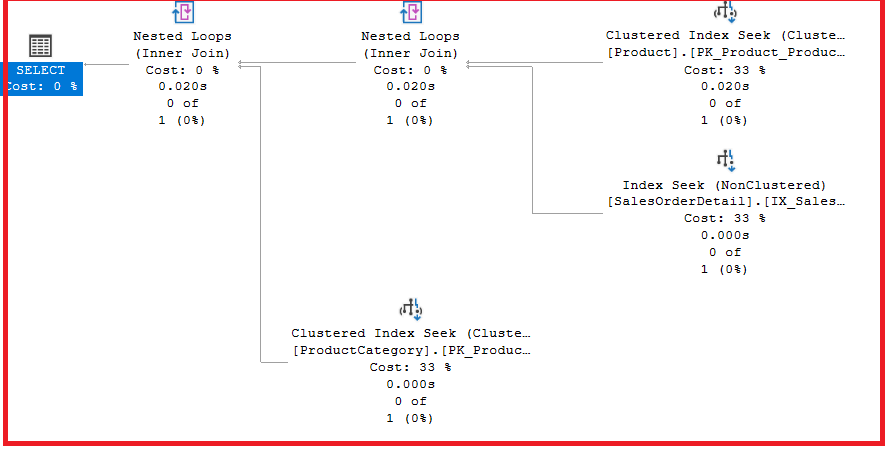
In the above query, 99% of the query execution time goes into the index seek operation, which is an important part of the optimization process.
Guidelines for choosing an index:
- Indexes should be made on keys frequently occurring in the WHERE clause and join statements.
- Indexes should not be made on frequently modified columns, i.e., columns to which the UPDATE command is frequently applied.
- Indexes should be made on Foreign keys where INSERT, UPDATE, and DELETE are concurrently performed. This allows UPDATES on the master table without shared locking on the weak entity.
- Indexes should be made on attributes commonly occurring together in the WHERE clause using the AND operator.
- Indexes should be made on ordering key values.
Selection
Selection of the rows that are required instead of selecting all the rows should be followed. SELECT * is highly inefficient as it scans the entire database.
SET STATISTICS TIME ON SELECT * FROM SalesLT.Product

SET STATISTICS TIME ON SELECT ProductNumber, Name, Color,Weight FROM SalesLT.Product

As we can see from the above two outputs, the time is reduced to one-fourth when we use the SELECT statement to select only those required columns.
Avoid using SELECT DISTINCT
The SELECT DISTINCT command in SQL fetches unique results and removes duplicate rows in the relation. To achieve this task, it groups related rows together and removes them. GROUP BY operation is a costly operation. So, to fetch distinct rows and remove duplicate rows, one might use more attributes in the SELECT operation.
Let us take an example,
SET STATISTICS TIME ON SELECT DISTINCT Name, Color, StandardCost, Weight FROM SalesLT.Product
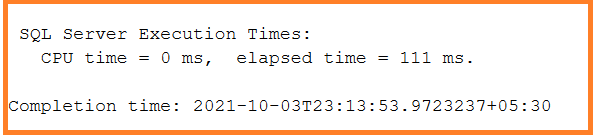
SET STATISTICS TIME ON SELECT Name, Color, StandardCost, Weight, SellEndDate, SellEndDate FROM SalesLT.Product
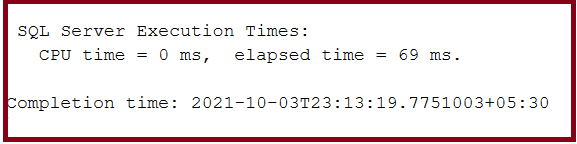
As we can see from the execution of the above two queries, the DISTINCT operation takes more time to fetch unique rows. So, it is better to add more attributes to the SELECT query to improve performance and get unique rows.
Inner joins vs. WHERE clause
We should use an inner join to merge two or more tables rather than the WHERE clause. WHERE clause creates the CROSS join/ CARTESIAN product for merging tables. CARTESIAN product of two tables takes a lot of time.
SET STATISTICS IO ON SELECT p.Name, Color, ListPrice FROM SalesLT.Product p, SalesLT.ProductCategory pc WHERE P.ProductCategoryID = pc.ProductCategoryID

SET STATISTICS TIME ON SELECT p.Name, Color, ListPrice FROM SalesLT.Product p INNER JOIN SalesLT.ProductCategory pc ON P.ProductCategoryID = pc.ProductCategoryID

So, the above outputs show that an inner join takes almost half the time of a join using a WHERE clause.
LIMIT command
The limit command is used to control the number of rows to be displayed from the result set. The result set needs to display only those rows that are required. Therefore, one must use a limit with the production dataset and provide an on-demand computation of rows for the production purpose
SET STATISTICS IO ON SELECT Name, Color, ListPrice FROM SalesLT.Product LIMIT 10
The above query prints the top 10 rows of the resultset. This drastically improves the performance of the query.
IN versus EXISTS
IN operator is more costly than EXISTS regarding scans, especially when the subquery result is a large dataset. So, we should try to use EXISTS rather than IN to fetch results with a subquery.
Let us see this with an example,
SET STATISTICS TIME ON
SELECT ProductNumber,Name,Color FROM SalesLT.Product WHERE ProductID IN (SELECT ProductID FROM SalesLT.ProductDescription)

SET STATISTICS TIME ON SELECT ProductNumber,Name,Color FROM SalesLT.Product WHERE EXISTS (SELECT ProductID FROM SalesLT.ProductDescription)
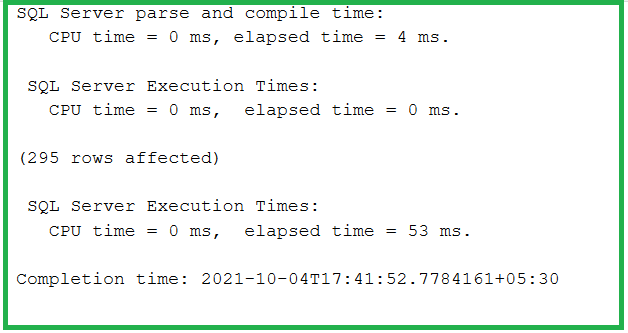
We have executed the same query having a subquery with IN command and EXISTS commands and we observe that the EXISTS command takes half of the time as compared to IN command and the number of physical and logical scans is very low.
Loops versus Bulk insert/update
Loops must be avoided because they require running the same query many times. Instead, we should opt for bulk inserts and updates.
SET STATISTICS TIME ON
DECLARE @Counter INT
SET @Counter=1
WHILE ( @Counter <= 10)
BEGIN
PRINT 'The counter value is = ' + CONVERT(VARCHAR,@Counter)
INSERT INTO [SalesLT].[ProductDescription]
([Description]
,[rowguid]
,[ModifiedDate])
VALUES
('This is great'
,NEWID()
,'12/01/2010')
SET @Counter = @Counter + 1
END
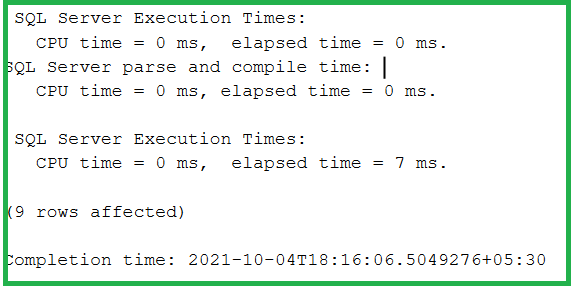
USE [AdventureWorksLT2019]
GO
SET STATISTICS TIME ON
INSERT INTO [SalesLT].[ProductDescription]
([Description]
,[rowguid]
,[ModifiedDate])
VALUES
('This is great'
,NEWID()
,'12/01/2010'),
('New news'
,NEWID()
,'12/01/2010'),
('Awesome product.'
,NEWID()
,'12/01/2010'),
..........,
('Awesome product.'
,NEWID()
,'12/01/2010')
GO
As we have seen above bulk insert works faster than loop statements.
Conclusion
SQL query optimization is a crucial process for ensuring the efficient performance of database systems. By enhancing query execution time, reducing resource consumption, and improving overall system scalability, optimization plays a key role in delivering a seamless user experience. This detailed guide has outlined the fundamental concepts and techniques for SQL query optimization, from understanding query processing to implementing practical optimization strategies.
Some other things to keep in mind:
- Avoid using correlated nested queries.
- Avoid inner joins with Equality or OR conditions.
- Check whether records exist before fetching them.
- Use indexing properly, and try to create more indexes for fetching composite columns.
-
Use Wildcards wisely.
-
Try to use WHERE rather than HAVING. Only use HAVING for aggregated values.
So, we learned how minor query changes can drastically improve their performance. This will boost the performance of applications and provide a better user experience. Keep all the guidelines in mind while writing queries.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
Frequently Asked Questions
A. Optimizing an SQL query involves various techniques to improve its performance and efficiency. Some common strategies include:
1. Indexing: Create appropriate indexes on columns used in WHERE, JOIN, and ORDER BY clauses to speed up data retrieval.
2. Filtering: Use efficient WHERE clauses to minimize the number of rows processed.
3. Avoid SELECT *: Retrieve only the necessary columns to reduce data transfer.
4. JOIN Optimization: Choose the most efficient JOIN type (INNER JOIN, LEFT JOIN, etc.) and ensure relevant columns are indexed.
5. Subqueries: Optimize subqueries to avoid excessive data processing.
6. Use EXISTS instead of IN: Replace IN clauses with EXISTS for better performance.
7. Limit Data: Use LIMIT or TOP to restrict the number of returned rows, especially for large result sets.
8. Denormalization: Consider denormalizing data for frequently accessed queries to reduce JOIN complexity.
9. Caching: Utilize query caching mechanisms provided by the database system.
10. Review Execution Plan: Analyze the query execution plan and optimize it if necessary using query hints.
11. Partitioning: If applicable, partition large tables to improve data retrieval for specific ranges.
Regularly monitoring query performance and profiling the database system can help identify bottlenecks and further optimize queries as needed.
A. The query optimization process involves analyzing SQL queries to improve their execution efficiency. It includes steps such as parsing the query, generating candidate execution plans, estimating costs for each plan, and selecting the most optimal plan based on cost estimations. Indexing, query rewriting, and other techniques are applied to reduce query execution time and improve overall database performance.
Computer science enthusiast








It's nice and informative...
Good content. Is there End to end SQL tutorial in youtube?