
AI Infrastructure Report for 2022 published
AI Infrastructure Report for 2022 published
Apple publishes StableDiffusion for CoreML, Reliability in Deep Learning, Humans in the Loop for AirBnB Listings

If you are reading one 100-page report this week, I recommend prioritizing this report for AI Infrastructure:
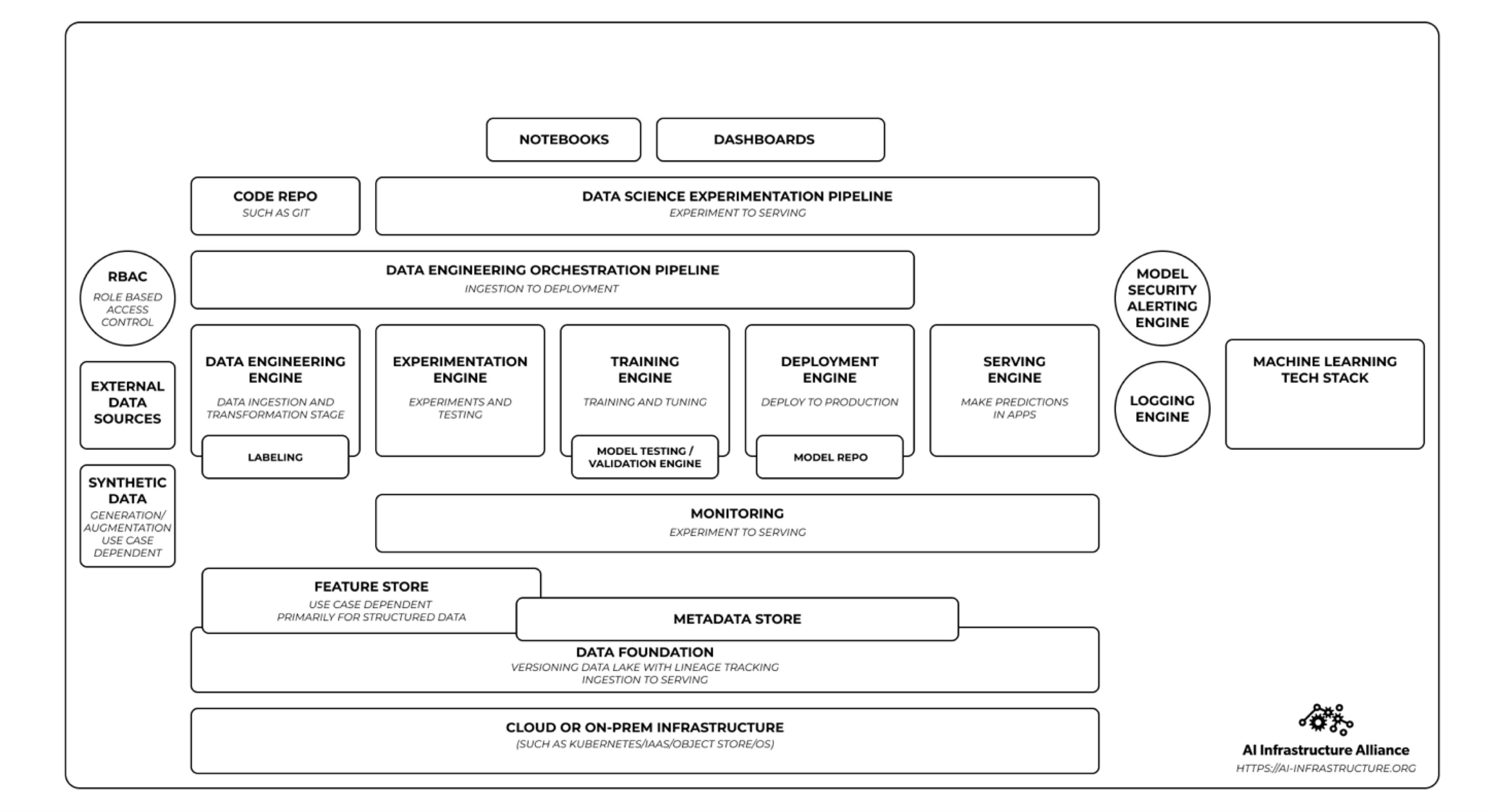
It talks a lot about the landscape and provide data points on the maturity and adoption level for different parts of the AI Infrastructure stack.
Articles

Apple announced optimizations for CoreML for popular stable diffusion library in here. The library that converts stable diffusion models into CoreML is available in GitHub.
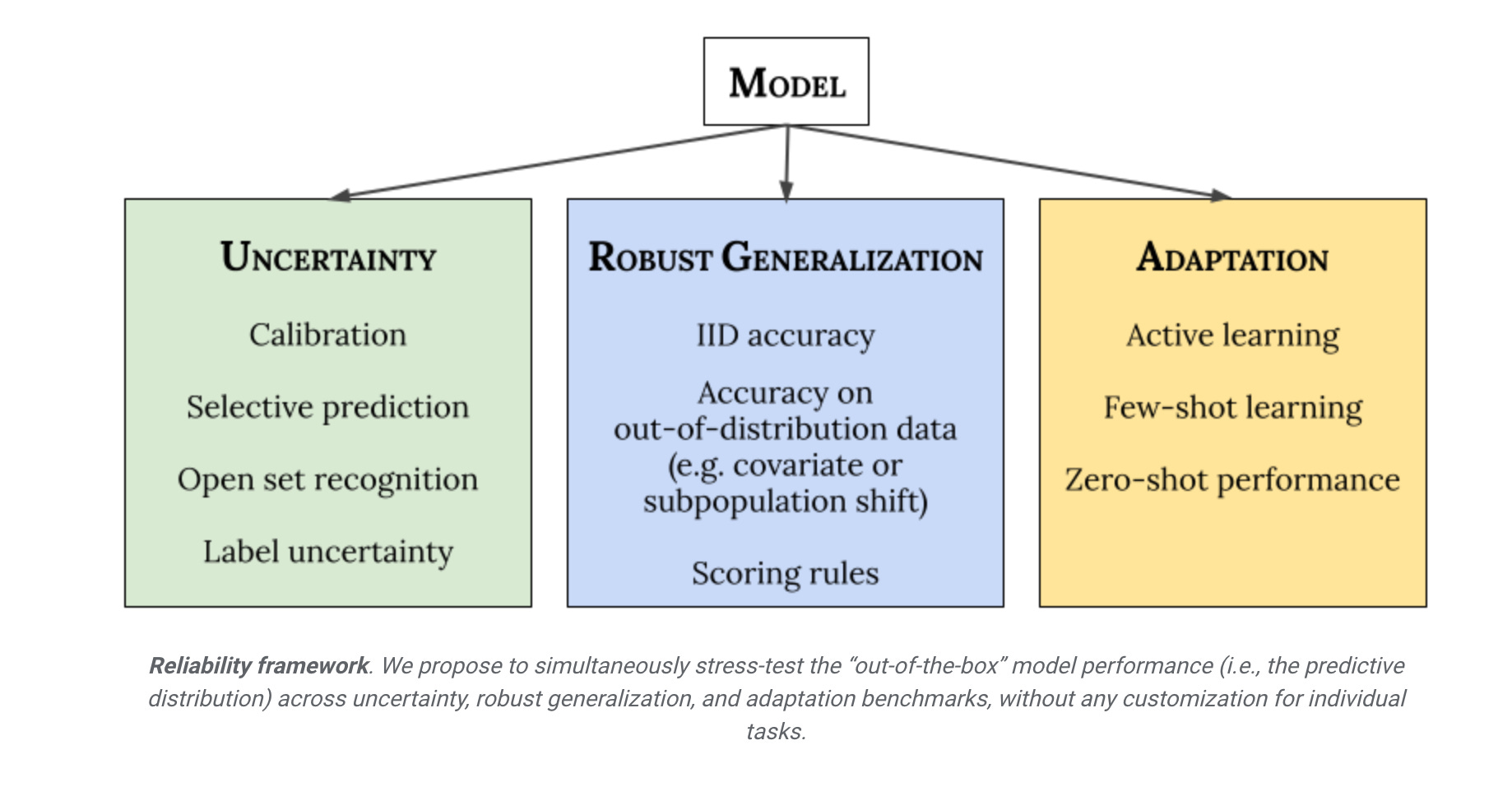
I recently stumbled upon a great blog post that talks about Reliability in Deep Learning Models from Google. They define main 3 different categories:
Uncertainty reflects the imperfect or unknown information that makes it difficult for a model to make accurate predictions. Predictive uncertainty quantification allows a model to compute optimal decisions and helps practitioners recognize when to trust the model’s predictions, thereby enabling graceful failures when the model is likely to be wrong.
Robust Generalization involves an estimate or forecast about an unseen event. We investigate four types of out-of-distribution data: covariate shift (when the input distribution changes between training and application and the output distribution is unchanged), semantic (or class) shift, label uncertainty, and subpopulation shift.
Adaptation refers to probing the model’s abilities over the course of its learning process. Benchmarks typically evaluate on static datasets with pre-defined train-test splits. However, in many applications, we are interested in models that can quickly adapt to new datasets and efficiently learn with as few labeled examples as possible.
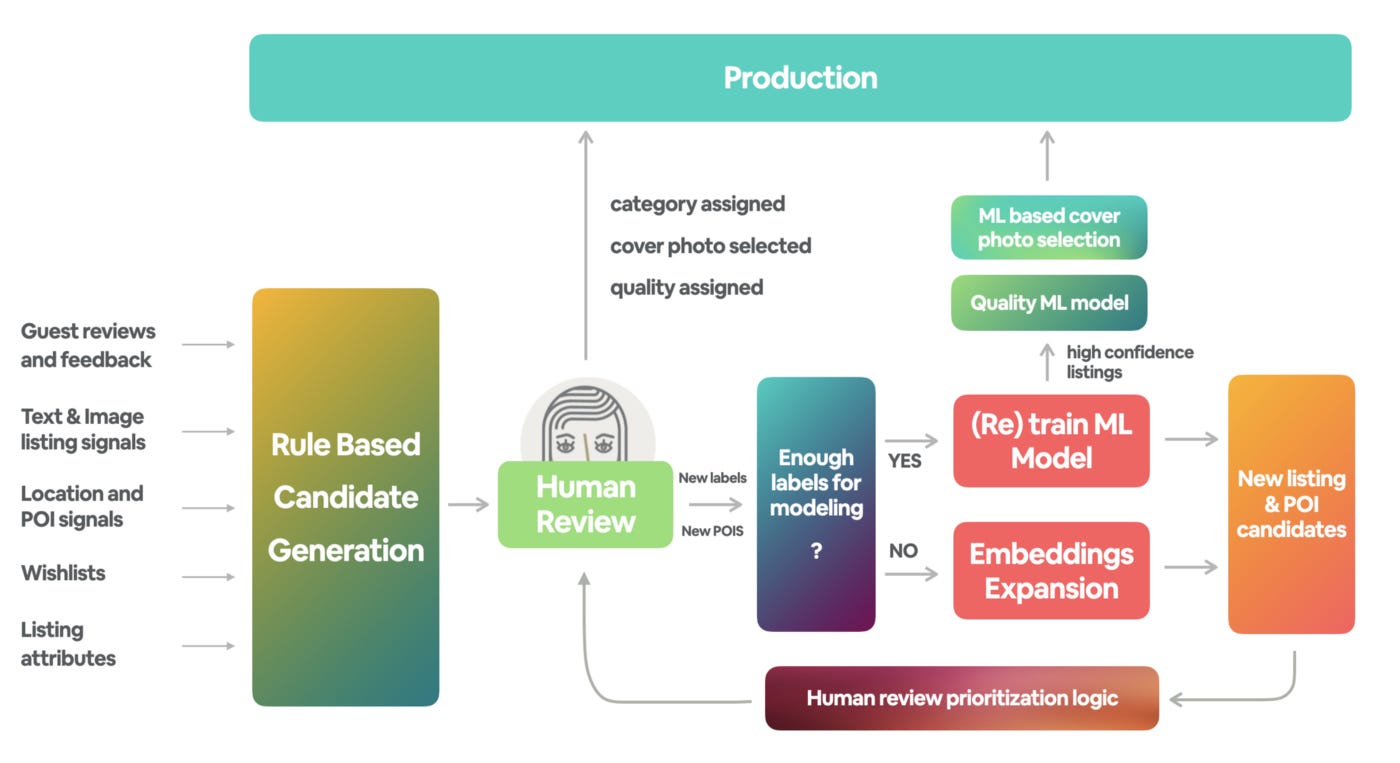
Airbnb showed how they use manual/human review for labeling different posts in the this blog post.
The manual review of candidates consists of several tasks. Given a listing candidate for a particular category or several categories, an agent would:
Confirm/reject the category or categories assigned to the listing by comparing it to the category definition.
Pick the photo that best represents the category. Listings can belong to multiple categories, so it is sometimes appropriate to pick a different photo to serve as the cover image for different categories.
Determine the quality tier of the selected photo. Specifically, we defined four quality tiers: Most Inspiring, High Quality, Acceptable Quality, and Low Quality. We use this information to rank the higher quality listings near the top of the results to achieve the “wow” effect with prospective guests.
Some of the categories rely on signals related to Places of Interest (POIs) data such as the locations of lakes or national parks, so the reviewers could add a POI that we were missing in our database.
After using the labels and categories, they use ML models for both ranking the listings as well as choosing the cover photo for the listing.

Google improved upon their data cards into a playbook and published a post on it. They provide a lot more structure on how companies should think about their data operations and provide distinct responsibilities for various modules:
In Ask, teams define transparency and optimize their dataset documentation for cross-functional decision-making. Participatory activities create opportunities for Data Card readers to have a say in what constitutes transparency in the dataset’s documentation. These address specific challenges and are rated for different intensities and durations so teams can mix-and-match activities around their needs.
The Inspect module contains activities to identify gaps and opportunities in dataset transparency and processes from user-centric and dataset-centric perspectives. It supports teams in refining, validating, and operationalizing Data Card templates across an organization so readers can arrive at reasonable conclusions about the datasets described.
The Answer module contains transparency patterns and dataset-exploration activities to answer challenging and ambiguous questions. Topics covered include preparing for transparency, writing reader-centric summaries in documentation, unpacking the usability and utility of datasets, and maintaining a Data Card over time.
The Audit module helps data teams and organizations set up processes to evaluate completed Data Cards before they are published. It also contains guidance to measure and track how a transparency effort for multiple datasets scales within organizations.
They have also various patterns where they provide some scaffolds such as foundations, transparency and so forth.
Libraries
Tensorflow has a Graph Neural Networks tutorial in Neurons 2022 and they made the material available in GitHub. The slides are also available in here. Couple of notebooks are also available in GitHub:
The videos to the tutorials are available in tutorial page. ICML version of this tutorial would be also similar vein for people who want to check out that version.
Click-through rate (CTR) prediction is a critical task for many industrial applications such as online advertising, recommender systems, and sponsored search. FuxiCTR provides an open-source library for CTR prediction, with key features in configurability, tunability, and reproducibility. We hope this project could benefit both researchers and practitioners with the goal of open benchmarking for CTR prediction.
Edward2 is a simple probabilistic programming language. It provides core utilities in deep learning ecosystems so that one can write models as probabilistic programs and manipulate a model's computation for flexible training and inference.
Objax is an open source machine learning framework that accelerates research and learning thanks to a minimalist object-oriented design and a readable code base. Its name comes from the contraction of Object and JAX -- a popular high-performance framework. Objax is designed by researchers for researchers with a focus on simplicity and understandability. Its users should be able to easily read, understand, extend, and modify it to fit their needs.
This library is the source code for the paper "Amos: An Adam-style Optimizer with Adaptive Weight Decay towards Model-Oriented Scale".
It implements Amos, an optimizer compatible with the optax library, and JEstimator, a light-weight library with a
tf.Estimator-like interface to manage T5X-compatible checkpoints for machine learning programs in Jax, which we use to run experiments in the paper.This package provides commands that make it easy to highlight terms in equations & add annotation labels (based on TikZ). Tested with pdflatex and lualatex, but should work with most other LaTeX engines such as xelatex as well.
The Beyond the Imitation Game Benchmark (BIG-bench) is a collaborative benchmark intended to probe large language models and extrapolate their future capabilities. The more than 200 tasks included in BIG-bench are summarized by keyword here, and by task name here. A paper introducing the benchmark, including evaluation results on large language models, is currently in preparation.
Stable Diffusion is a latent text-to-image diffusion model. Thanks to a generous compute donation from Stability AI and support from LAION, we were able to train a Latent Diffusion Model on 512x512 images from a subset of the LAION-5B database. Similar to Google's Imagen, this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM.
This repository contains Stable Diffusion models trained from scratch and will be continuously updated with new checkpoints. The following list provides an overview of all currently available models.
Scenic is a library with a focus on research around attention-based models for computer vision. Scenic has been successfully used to develop classification, segmentation, and detection models for multiple modalities including images, video, audio, and multimodal combinations of them.
Betty is a PyTorch library for generalized meta-learning (GML) and multilevel optimization (MLO) that allows a simple and modular programming interface for a number of large-scale applications including meta-learning, hyperparameter optimization, neural architecture search, data reweighting, and many more.
DeepFashion-MultiModal is a large-scale high-quality human dataset with rich multi-modal annotations. It has the following properties:
It contains 44,096 high-resolution human images, including 12,701 full body human images.
For each full body images, we manually annotate the human parsing labels of 24 classes.
For each full body images, we manually annotate the keypoints.
We extract DensePose for each human image.
Each image is manually annotated with attributes for both clothes shapes and textures.
We provide a textual description for each image.
DoWhy is a Python library for causal inference that supports explicit modeling and testing of causal assumptions. DoWhy is based on a unified language for causal inference, combining causal graphical models and potential outcomes frameworks.