Setting your ML project up for success
What can you do to maximize probability of success for your Machine Learning solution? Throughout my 15 years as data scientist in academia, big pharma and through consulting, one common theme has emerged: the most reliable predictor of success for any NLP or ML-based solution is whether or not you involve the data science team early on. By introducing your data scientists to the domain experts right from the start of the project, you can iteratively refine and improve both your data and your ML models.
I've worked on a few projects throughout the years where data was pretty much just thrown at me so I could go "model it" and "predict something", whatever that may be. Sometimes, I got lucky and was able to track someone down who at least could tell me a little bit about the source of that data, and who could explain funny quirks like "Oh yea, this overrepresented category X is what the app showed by default and most users probably didn't bother going through the drop-down list properly". Great.
To my dear friends & colleagues in Business Intelligence, Analytics or Product Development: please, please, please, get your data scientists involved as early as you can. That includes the data collection and/or annotation step. You can not possibly overestimate how crucial it is to make sure the data is consistent and meaningful, and suitable to be processed by NLP/ML algorithms down the line.
I think back fondly on those times where I got to work with domain experts right from the start, and where we got to build something from the ground up together. Like when I worked with Dóra Szakonyi, Stefanie De Bodt and other plant researchers at VIB/UGent to build an annotation framework for scientific literature covering leaf growth and development. Or when Sampo Pyysalo, Filip Ginter and myself dove into the wonderful world of cell lines and cell types, expertly guided by Suwisa Kaewphan and Tomoko Ohta. At J&J, I got the opportunity to lead a large-scale annotation effort on clinical trial abstracts, bridging between domain experts on the one hand, and the DS team building models on the other hand. What all of these opportunities had in common, is that as a data scientist, you learn SO MUCH working together with the actual domain experts on the data & use-case that you want to model. And as you grow throughout these opportunities, you start understanding what it takes to pull together a decent dataset:
Are you making sure to avoid biases from the get-go, as much as you can? How will data be collected, by whom, and what motive do users have to fill in certain fields? (don't get me started on diagnose codes in Real World Evidence data!) How can data be anonymized while still preserving relevant correlations? Which features will be important to inform the modeling later on? How will you evaluate "success" of the project at the end?
Then the fun bit: you get your hands on the first data points and you eagerly start building models. You run into unfulfilled hypotheses. Your model outputs strange predictions. You track oddities in the training data. But most importantly: you discuss all of these results with your domain expert, and together you iterate back on the data model - rinse and repeat.
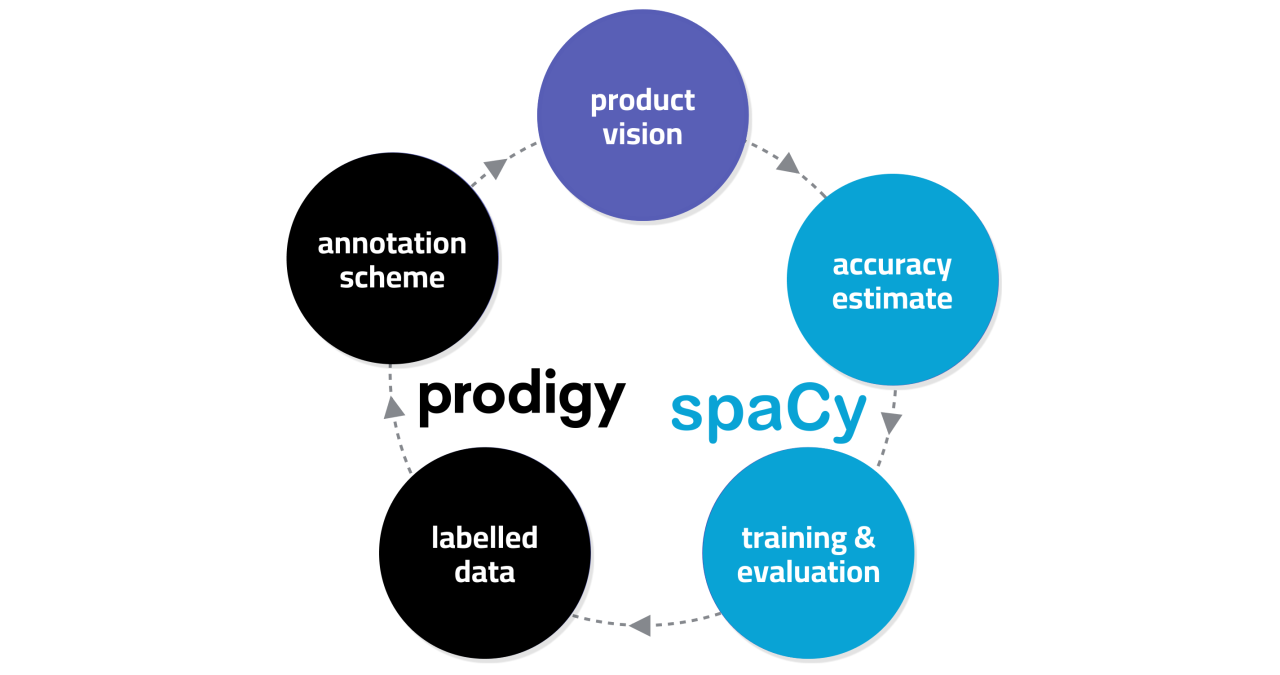
I started working on the NLP library spaCy 4 years ago, and it's been an extremely fun ride to be coding for an open-source toolbox that so many developers use to implement production-ready NLP solutions. It's been fun and gratifying, and still very much is, but I only realised this year that something had been lacking. This year's launch of our consulting services over at Explosion made me realise again how rewarding and valuable it is to be directly connected to actual business cases and domain experts, setting up projects for success right from the start. That includes making sure that data collection and annotation is done with the necessary care and consideration. It's what drew me to Explosion to begin with: the seamless integration between the NLP toolkit spaCy and the scriptable annotation framework Prodigy ensures that you can iterate quickly on your data and your NLP algorithms/models.
I hope all data scientists will agree: we're in it to solve actual business problems, to unlock valuable patterns and insights from data to refine business processes, to empower domain experts with automated insights or suggestions so they can do their job more efficiently. So don't let these data scientists sit idly by while you collect the data. Get them involved, introduce them to the domain experts and make sure you iterate on both the data and the ML models until you've identified a solution that truly works for your business case. Your final solution will be so much more robust, useful and meaningful. Consider it your first newyear's resolution for 2023! ;-)
Senior Data Scientist | NLP | Digital Transformation
1yHumm interesting!
Head of Developer Growth at Weaviate
1yCircle of a successful machine learning project?
CTO @ BioLizard / on the exciting crossroad between software, data & life sciences
1yAbsolutely spot on. Deep collaboration, and mutual understanding, between domain experts and data scientists from the start is key. And it works both ways: I have seen projects fail because they were led by data scientists, and they did not involve the domain experts early enough and sufficiently well.
Big Data Platform Architect at SABIC | AI/ML Services Architecture and Solutions | SAP & ERP Enterprise Solutions | Business Carve-Out Design & Implementation
1yThanks for posting
Machine Learning Engineer | Data Science Mentor at ADPList | Big Data and MLOps | Support Ukraine on u24.gov.ua 💛💙
1yI just got an idea about using Prodigy for a personal project of OCR for historical documents but then realized that it's not for free (you guys spoiled us with spaCy 😅). In any case, it looks like an amazing tool and I will be cheering for Explosion in 2023.