Dillon Laird is an Engineering Manager at Landing AI where he leads the machine learning team. He presented the session “LandingLens: A Journey in Democratizing AI” at Snorkel AI’s 2022 Future of Data-Centric AI (FDCAI) Conference. A transcript of his talk is provided below. It has been lightly edited for reading clarity.
Today, I will be introducing you to LandingLens, our main product, and taking you through the journey we went through in developing that product and the data-centric approaches we’ve incorporated into the platform.

LandingLens is an ML platform that we built which enables our customers, oftentimes non-engineers, to use AI to solve their problems. These are people in different industries who have real-world problems, like a manufacturer who might want to build an AI system to inspect defects.
Our customers are all over the place. Manufacturing is the main one we work with, as well as agriculture and pharmaceuticals. Across industries, we have found that they have three objectives that they’re trying to work on.
First is reduce inspection costs. Say you’re a manufacturer and you’re producing an item. You have to pay for a system to inspect that item for defects so you don’t ship defective products. Oftentimes that inspection process is pretty costly, so if you can automate that with a machine learning system, you can reduce that cost.
Another objective is often improving quality. This could be decreasing false positives or false negatives, false negatives being an item which comes in it has a defect on it and you accidentally classify that item as okay and ship it to your customer. Obviously, you don’t want to do that.
The third objective is to help our customers get the most from their existing ML platforms. They can be pretty costly to deploy, or maybe they’re flagging a lot of products as defective when they’re actually not, and it causes them to have to reinspect the item again. We can help reduce setup costs and make the whole process a lot easier.

When we initially approached these problems with our customers, we didn’t start off with the platform. The first thing we did was we focused on one vertical: in our case, it was manufacturing. We actually ended up building custom solutions for our customers. We initially thought this was going be a really easy problem to solve, but it was not. We quickly started to find all the difficulties with doing custom work and developed processes for quickly completing these projects. We also started to build some of the initial items that would later evolve into the platform, such as labeling tools and modeling frameworks for training our models. As we were doing this, we started to very quickly run into big challenges, particularly in this manufacturing area.

One of those challenges was ambiguous labels. Oftentimes you’re working with a manufacturer who might have an existing inspection process where they’re actually looking at the physical part to determine if there’s a defect. Obviously, if you’ve moved to an automated system that uses machine learning, you have to move to digital images instead of looking at the physical part. You can lose a lot of information there and end up with some weird-looking side cases where it’s not clear if this product should be okay or if that product should be not so good.
Another problem is very small data sets, which occur for two reasons. One is that manufacturers are not trying to produce defective products! Therefore, there are not a lot of images of defective products. The other problem is that it takes a lot of resources to label a lot of images. So as we’re working on training these ML platforms, we don’t have one million image data sets that you might see in academia or at these big tech companies. We were typically working in the range of hundreds or thousands of images.
Another problem is that, for customers who have machine learning solutions already but want to improve them, it was very slow time-to-deploy. There weren’t really best practices for how to get something into production, how to make sure that it was working correctly, or even how to iterate on the model initially to get it to the right performance level.
To solve these problems, we developed two big breakthroughs that helped us with our manufacturing customers: The ML Life Cycle, and data-centric AI.
The ML life cycle is broken down into three stages: data, model, and deploy. What’s most important is being able to iterate from each stage to the other: training model feeds back to the data, the deployment back to the training model or the data collection, and so on.
Our second breakthrough is the data-centric approach. When I’m analyzing the model results and I’m going back to that data section, what exactly am I doing? How am I modifying that data to improve the model performance?
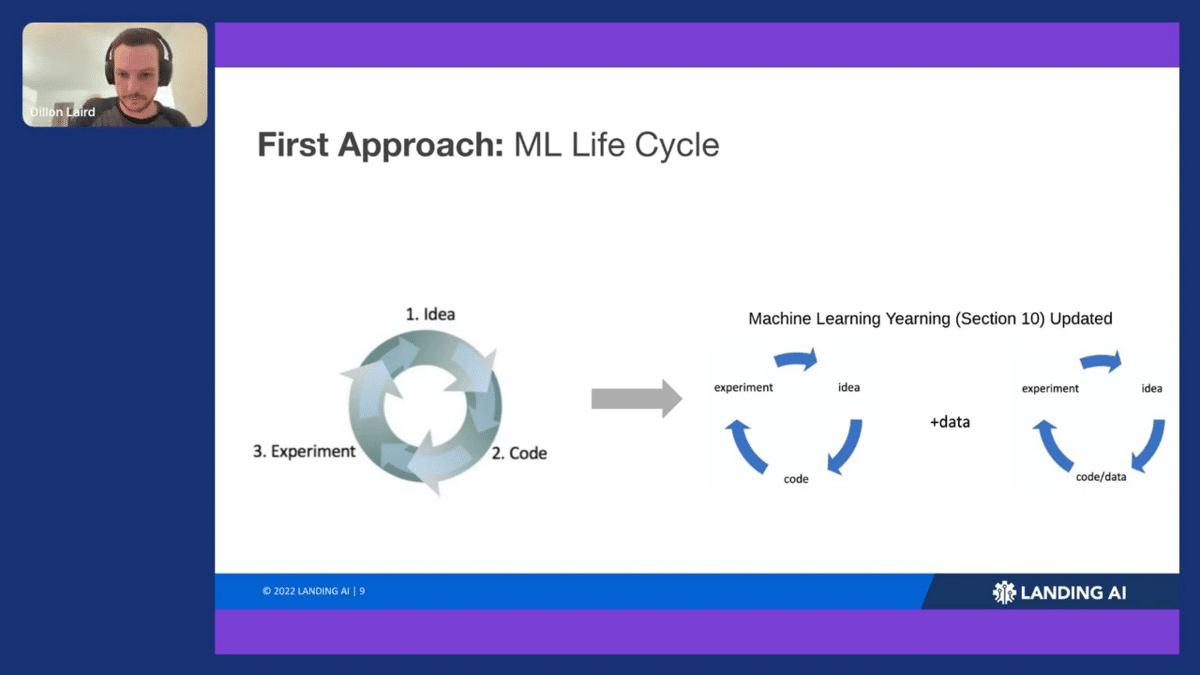
The idea of the ML lifecycle came from the Andrew Ng book Machine Learning Yearning (and if you haven’t read that, I strongly encourage you to check it out.) In Chapter 10, he talks about the iteration cycle of building a machine learning project wherein you begin with an idea, then you code up that idea, and then you run an experiment. From that experiment, you analyze the results and you come up with another idea.
What we found after building the main code base was that we actually weren’t going back to modify the code. We were going back to modify the data. We updated his ML cycle to run from idea to data to experiment, and that was the real beginning for our life cycle breakthrough.
In an example of one of our earlier projects, you can see that life cycle reflected in the time allocated to different parts of the project.
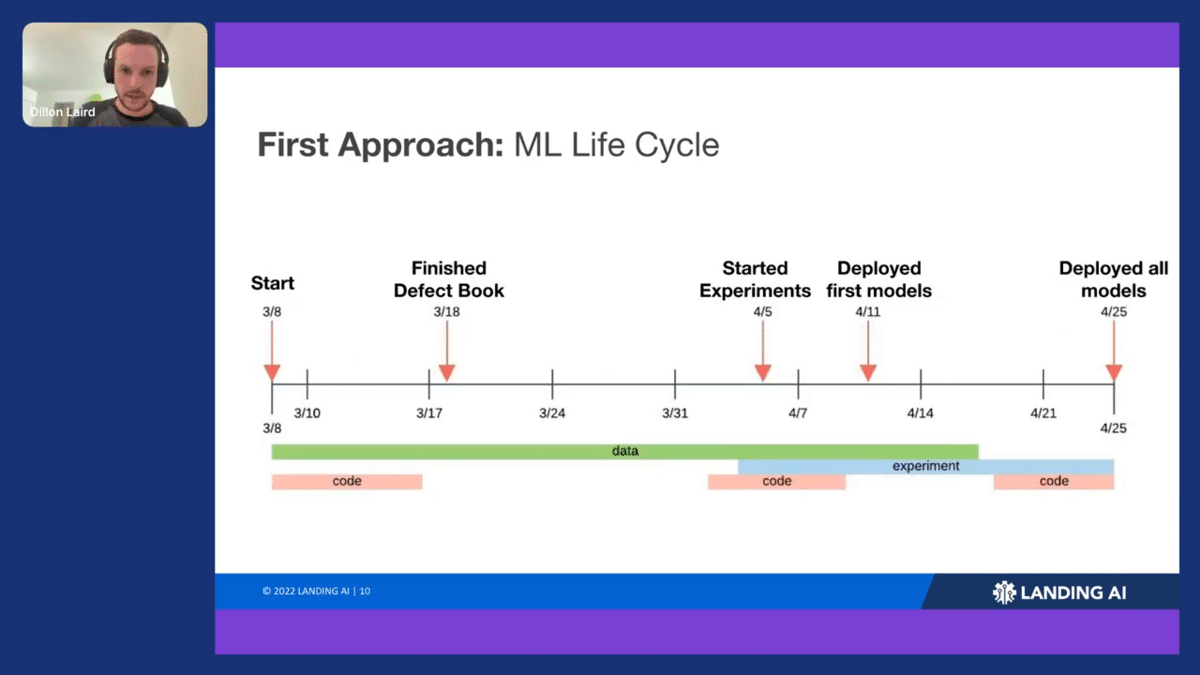
This particular project took about two months to complete. When we started off, we were building some initial code bases for training the model, maybe analyzing the data. But the first objective is building that defect book. You really want to figure out better label definitions early on to avoid complications from ambiguous labels. After you finish the defect book, you’re gonna start labeling the data and ensure that it’s labeled correctly based on what you’ve outlined in the defect book. Next, you start your experiments.
After running our experiments, we found that instead of updating hyperparameters or trying new architectures, we were going back and updating the data. We were uncovering mislabeled data, finding a lot of added distribution data that we had to figure out what to do with. Coding does come back around too, for example before deployment, but at the end of the day, we spent 50% or more of our project time just cleaning the data itself.
One of the data dives we took was asking the inspectors from the manufacturing client to label the same set of data as we were working on. We found big discrepancies between what they were seeing as defective and not. In one case, one inspector had 0% escape (i.e. ratio of false negatives) while another labeler had 30% escape within the same data set. We were targeting near 0% escapes, so if we were to start off with those kind of definitions, we could never achieve our objectives.
Coming off of these projects, we started to piece together a very detailed outline of how we wanted to do these projects in the future and what we could do to make them efficient. We called this the AVI ML Life Cycle, which stands for automated visual inspection. This was often how we would go through projects.
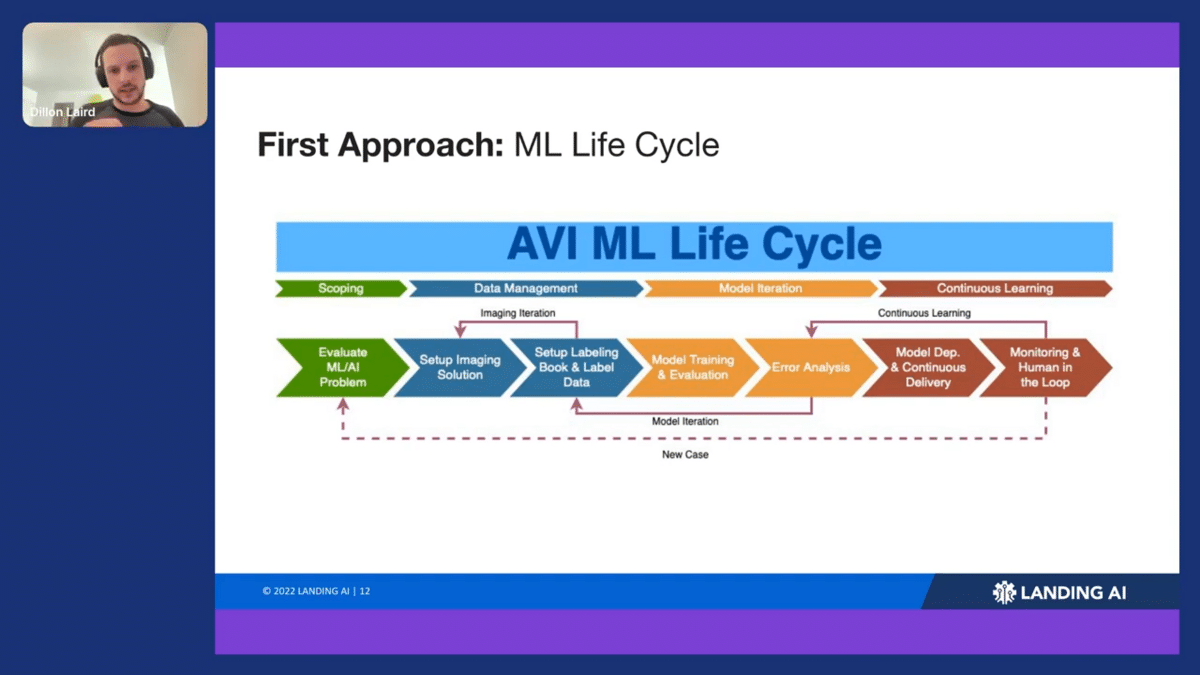
First, you scope out the project and evaluate the ML problem to be solved. Then, you move into the data section, which often starts with setting up the imaging solution. This step is extremely important because if you don’t have the right resolution and the right lighting, you’re never gonna be able to get an ML model that will classify those images.
Then you go on to setting up the defect book, labeling the data, and then you move into model training and error analysis, i.e. analyzing the errors that a particular model has had.
There are some key loopbacks here too. From error analysis, you go back to labeling data: we call this line “model iteration.” We’re often going back to update the data to then improve the model results. We have another loop we call “continuous learning”, which is the deployment part. These loops are esssentially the three constructs that Andrew defines: data, model training, and deployment.

But this wasn’t the full picture yet. The tricky part here is, how do you actually loop back? What do you do there? What actions do you take? How do what do you do with the data to improve the model results? I will again recommend Andrew’s book for a deep dive of best practices, but we identified a few key actions he suggests that were key to our problems, namely using consensus labeling to spot inconsistencies and running error analysis on subsets of data.

We were doing these projects manually, which obviously wasn’t a very scalable approach. We couldn’t hire a new machine learning engineer every time we wanted to work with a new customer. On top of that, while we had a code base, we were still producing lots of non-reusable code, right? Each project was slightly different, and that created a lot of maintenance work. Finally, while we were able to get some of these timelines down to two months to complete these POCs, it was actually still too slow for what our customers wanted to do. We really needed to speed that up as well.
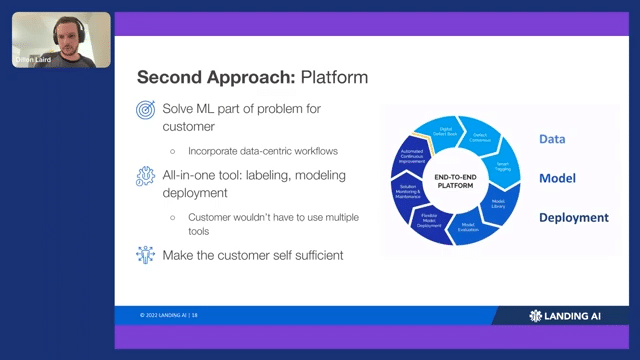
That brings us to our second approach: our platform. We really wanted the platform to be able to solve or take care of that ML part for our customers. If you remember before, our customers are not necessarily machine learning engineers, so you don’t want them to have to deal with the ML part. We also wanted an all-in-one tool. We don’t want our customers to have to get into chain labeling with their own modeling code and then use another library for deployment—we want it all-in-one. Finally, we want to make them self-sufficient. We want to provide as much context as we can for them so they don’t have to learn a whole new field of ML or how to figure out mislabeled data on their own.
There are three main components of the platform, data, model and deployment. You can see that lifecycle is baked right into the platform. One of the tips that Andrew talks about, using consensus labeling, is another core feature of the platform. You can have multiple subject matter experts label the same data and figuring out very early on where they’re matching up and where they differ in their opinion.
Another tip we baked in was using error analysis. You can click into a section and analyze different slices of your data. Say you’re trying to figure out, “Hey, on this particular data set, what are my false negatives?” You can go back and look at that data and relabel it to fix your data problems.

Before we launched the platform, our manual approach was taking roughly two months (with some high variance depending on the project) to complete. As a result of launching the platform, we’ve been able to do the same amount of work in two days. You simply do not have to code up as much. It’s much more streamlined – you’re going directly from model results back into updating your data.
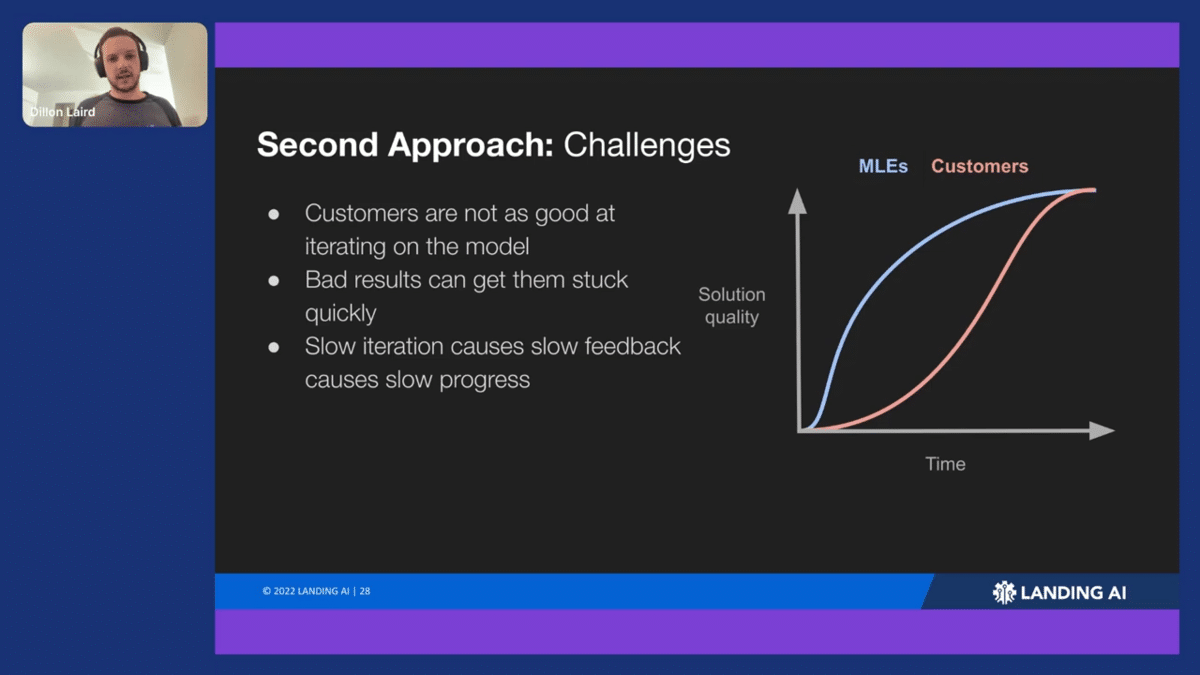
There were still some ongoing challenges, so we weren’t totally out of the water. One of the issues was reaching the solution quality that we wanted efficiently. if you looked at a graph of time versus solution quality, or accuracy or precision of your model, it was still taking our customer quite a long time to get to the solution quality we want. We also had to help them out quite a lot along the way. If you looked at our machine learning engineers on the same project, they were reaching this quality a lot faster. We were learning that our customers were not MLEs, but people who have real-world problems that they need ML to solve. They just don’t have the knowledge to iterate on the model like an MLE might.
You can also get stuck early on if you don’t know how to read loss curves or how models learn and what to look for in terms of issues with data. If I’m a customer and I were to label my data, think it’s good, hit “train” and suddenly get 10% accuracy, I don’t really know what to do next. An MLE might be able to say, oh, your loss curves off, so you need to bump up your augmentation or something like that, but customers don’t have that expertise.
On top of this, we’re a cloud-based platform. The slower iteration can also cause really slow feedback. If you can’t, in one sitting, hit train and see your model results and then update your data, you’re probably gonna leave, come back an hour later and it’s going to take a very long time to iterate—especially if you’re not making optimal decisions per iteration.
To solve these problems, we actually had to focus back on the ML side of things instead of the dataset side of things. We really wanted to do this so that our customers didn’t have to focus on ML and could instead look at the data part.
Our first main objective was faster iteration. You can’t have people not being able to see the results in one sitting, and you have to have good out-of-box performance. You can’t have a side case where a customer trains a model and then after the fact we give feedback like, “oh, you should have run for more epochs, you should have tuned this hyperparameter.” And if the training takes more than one sitting, it’s going to cause an exaggerated slowdown. If it takes you 20 minutes, you’re not gonna wait there for 20 minutes for the results to pop back up, you’ll come back in an hour or so. That could be the difference between making three to five iterations a day versus one iteration a day. We worked on a lot of different aspects to quickly improve that speed from around 20 minutes to less than a few minutes.
In a cloud platform you want to focus on two things: your infrastructure and your training time. Your infrastructure is how do you keep costs down—do you get a big beefy GPU, or do you get very small GPUs? How long do you keep them warm, and what does that cost? Can you spin them up really quickly? With training time, it’s not just about speeding up training, but also providing out of the box performance.
AI equals code plus data. If you’re good at the code part, as an MLE might be, you can really focus on the data and make meaningful improvements. But if you’re not and MLE and don’t have that knowledge, the code part can become a huge bottleneck for you and could really slow you down. It was up to us to improve this. Looking at our customers’ projects, accuracy over the frequency of them getting that accuracy on the first iteration versus the second iteration, you can see how if you get bad performance initially, you’re gonna get stuck. You’re not going to know how to improve that.
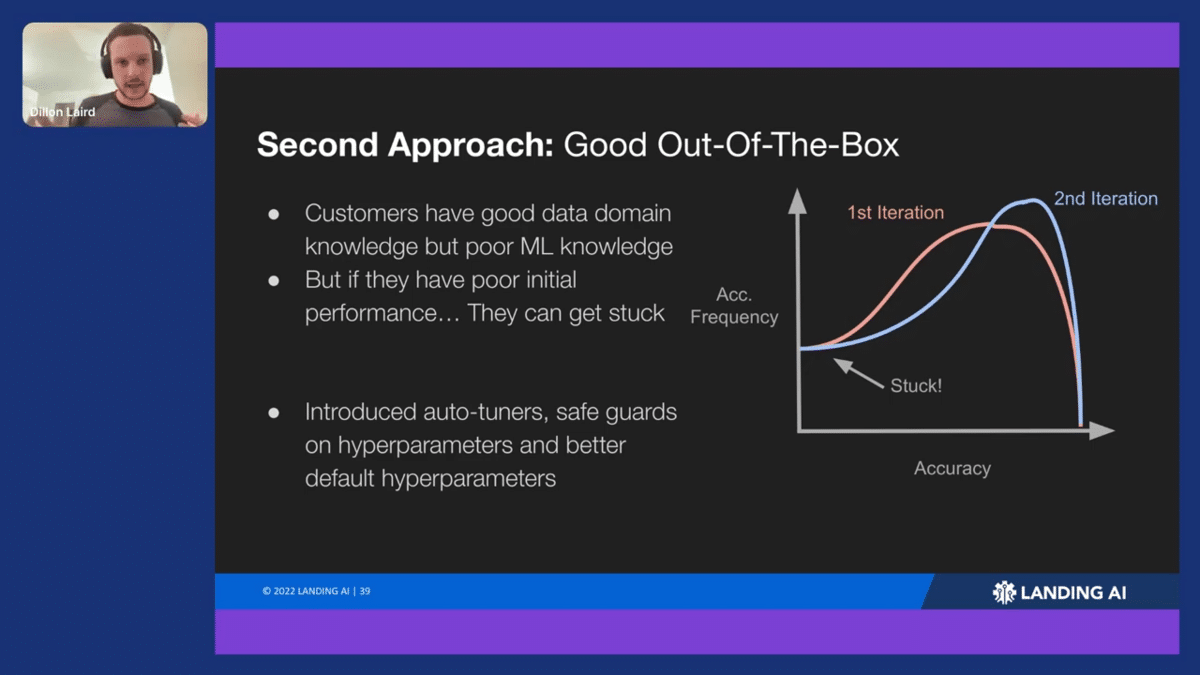
What we really needed to do here was to go case-by-case and look at all the different side cases to identify what kind of data our customers were running on and what kind of labels they had to try to build a better out-of-the box experience. It fell into three areas, the first being auto-tuners. Iis there anything I can do to look at that data ahead of time and figure out what I should set the hyperparameters to so that you get a good initial experience? The second one is safeguarding on hyperparameters. You need some adjustability on the hyperparameters, but if I, for example, offer you a tool to adjust the brightness for, as a data augmentation, you probably do not want, pure white images or extremely dark images going to the model, because it’s not going to help out. We wanted to set up sane safeguards on those hyperparameters.
The third area to build a better out-of-the-box experience was better default parameters. You get these models from academia and they work really well on ImageNet, but we are so far away from the ImageNet distribution that they just do not transfer very well. We’re trying to work with the data distributions that our customers have, and the data set sizes our customers have to make sure our models work well for that type of data.
In doing this, you eliminate that whole coding problem for the customer. Through the platform, they can be better at the algorithm part and because of that, they have more time to focus on the data, which is really where they are the real experts, right? They look at this data all the time and they should be embedding their knowledge into that data set and the labels.
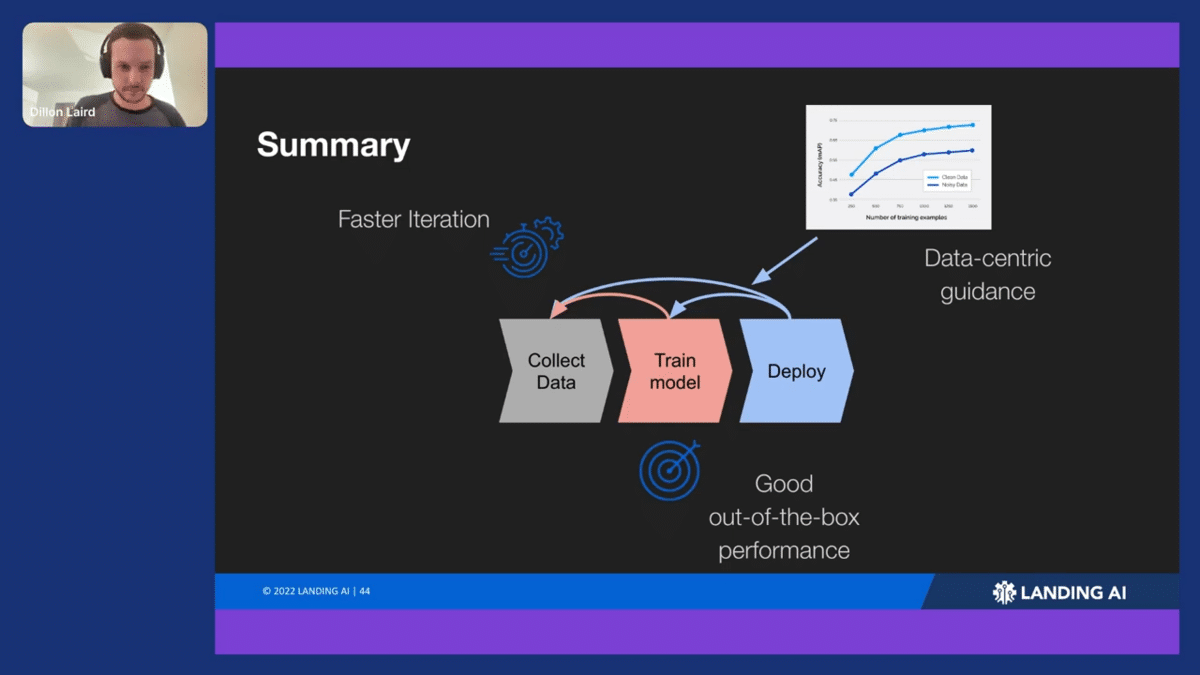
To summarize, initially we developed this process, this ML life cycle with these three main steps. Andrew talks about this data-centric approach, which we tried to embed that into the platform to help guide our customers to use data-centric approaches to go through this cycle. We also want to ensure that they can go through the cycle quickly, so they’re not getting bottlenecked on the training process. We also want to make sure they’re able to step through without getting stuck. If they have a bad performance out of the train model, they can’t go to the deployment phase, so we wanted to make that initial experience a lot easier.
Finally, while we’ve worked on these problems, there are still a lot of big remaining open problems that we’re still trying to tackle. There’s lots of literature on these topics in academia, but even taking that and transferring it to the data sets that our customers can use is its own challenge.
One of the issues is small data. We talked about how they don’t produce defective items on purpose, but they definitely need an automated system to capture the defective items they do create. How do you deal with that small amount of data there?
Automated labeling is a big problem for our customers. They don’t have huge labeling teams and they don’t want to spend a lot of money on labeling. But DL is a very data-hungry type of machine learning solution, so how do you increase the labeling throughput?
Finally, helping them find data issues automatically. It’s still a bit of a struggle to figure out, oh, should this label be in this position or that, or should I cover this defect here and not this similar-looking thing here. How do we automatically detect these issues in the data for the customer?
Q & A for LandingLens presentation
Aarti Bagul: Amazing, thank you so much, Dillon! It’s exciting to see all the iterations that you’ve come through. I know when I worked there, we were at the first iteration, so it was good to see that live, but it’s exciting to see the progression.
We may have time for questions, so I’ll just ask a couple. People are really liking that you hopped that speed up from two months to two days. But in general, how long does it take for your customers, if they’re starting from scratch defining the type of defects that they want to capture etc., to getting to a model that they are happy with? How long is that time generally?
Dillon Laird: Yeah, that’s a great question. It’s highly variable, I’ll say that. It can be two minutes, given that you have the right imaging setup and you have a good sense of what types of defects you want to identify. So in that instance, I gave there, they already had a good imaging setup and we had that all sorted out. But it can definitely take longer, right? If you don’t have the right camera setup, for example, you might have to hire a team to set up that camera, to take images of the defects, to make sure that you can identify those properly. Obviously that process itself can take a couple weeks to a month or more.
Once that’s done and you’re in the platform, we do generally see it in less than two weeks.
AB: Awesome. We have a question: what data types or modalities are the most challenging? I know you mostly work with images, so a better question framing might be, what sort of types of defects or types of products are the most challenging to work with?
DL: Yeah, that, that’s a great question. They can all be challenging, but I’ll just talk about some of the key differences between the general data distribution that we work with versus the ones like ImageNet. One key difference is our images are typically a lot larger. A lot of times you do have customers with these big cameras and you’re looking at a pretty big image, especially if it’s an electronic device. The second key aspect there is the defects you’re looking at are very small. So not only do you have a huge image, you got a really tiny defect that you know is maybe four pixels by four pixels on that image that you have to detect. You can think of all the challenges that causes.
AB: Makes sense. Definitely. Also in the contrast between the defect I imagine when we would track it on lenses, like that’s just like really hard for a human to see, let alone a machine or like an ML model.
Thank you so much, Dillon, for being here with us and taking us on this journey of LandingLens!
DL: Awesome. Thanks for having me.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.