Peter Mattson is a senior staff engineer at Google and president of MLCommons.org. He presented “MLCommons and Public Datasets” at Snorkel AI’s The Future of Data-Centric AI Summit in 2022. His talk was followed by an audience Q&A moderated by SnorkelAI’s Aarti Bagul. A transcript of the talk follows. It has been lightly edited for reading clarity.

I’m very excited to be here and talk a bit about the ML Commons Association and what we are doing to try and build the future of public datasets.
Briefly, what is the ML Commons Association?

MLCommons is a nonprofit that brings together a broad community of large companies, small companies, and academics from around the globe with a common mission. Our mission is to help build the ecosystem that transforms machine learning from where it is today, which in my mind is just past the Wright brothers, so to speak—we’ve created something incredible and we are still learning how to make it work and how to transform it into value for everyone—into something like the airline industry. Something that everybody uses, is incredibly reliable, and enables people to do things they couldn’t do otherwise.
In order to do this, ML Commons works through three main pillars of contribution. Those pillars are 1) benchmarks—ways of measuring everything from speed to accuracy, to data quality, to efficiency, 2) best practices—standard processes and means of inter-operating various tools, and most importantly to this discussion, 3) data.
We believe data is at the heart of ML and we are very interested in helping everyone come together as a community and move the data forward. So, why data? Why is this the heart of everything that we do both at MLCommons and as the machine learning community?

The phrase that, to me, sums this up is that data is the new code.
Data defines the best possible functionality of a machine learning solution. You cannot do better than your data. What the model does is serve as a lossy compiler. It takes the functionality encoded in your data and extracts it into an executable form as best it can. The better the model, the better executable you get. Your ultimate limit is determined by the data.

We know that building datasets is hard and that bad data is a major risk. When you’re building a dataset, you always have to be asking questions like, what data do you have? What new data should you acquire or label to supplement that data? Are there errors in your labels? How do you control your costs through this process, such as for labeling or compute and so on? This is a complex set of technical challenges and tradeoffs.
Perhaps most importantly, does your test data, the data that you’re using to evaluate your solution, sufficiently represent the real-world problem you are trying to solve? Too often we think of doing great on the test data as having built a great solution, and this is not true.
Here’s a real-world example. This is a famous bridge in the state of Washington. They did, I’m sure, a lot of engineering and modeling before they built it, but they missed a critical test case—high winds. As a result, they had a significant problem. The same sort of thing can happen to machine learning models. Bad data produces poorly trained models, and this leads to bad outcomes. In particular, if your bad data is in your test data, you won’t see these outcomes coming.
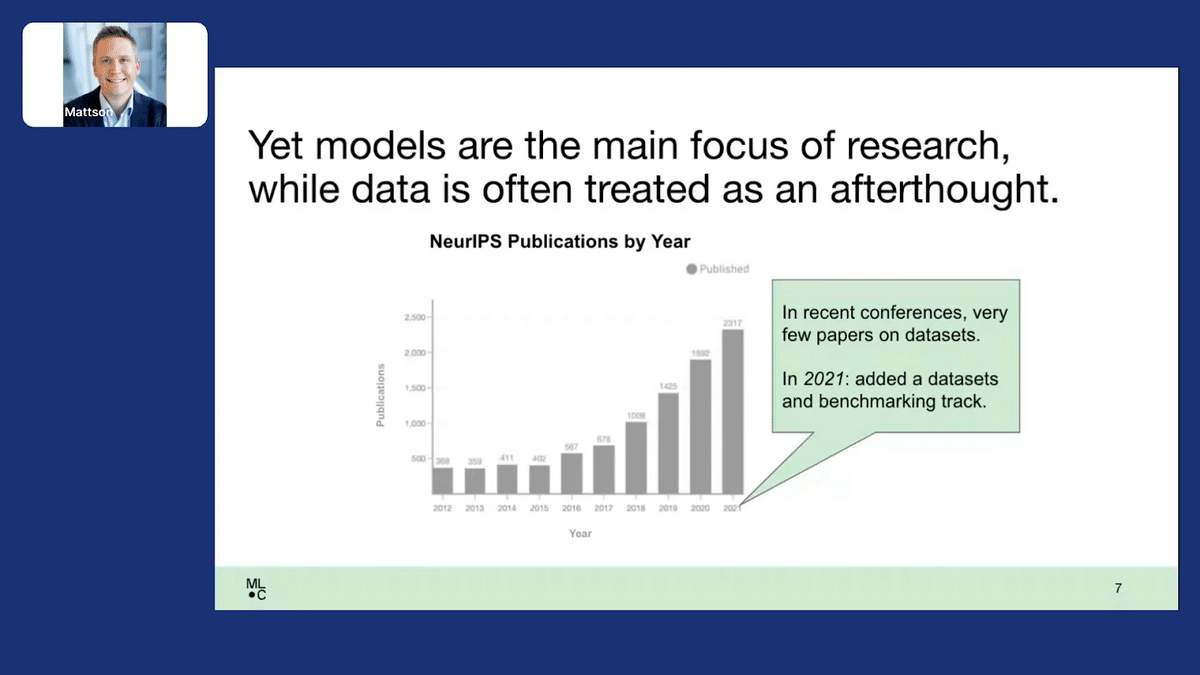
Despite knowing how vital data is and how hard it is to get right, models remain the main focus of research. Conferences like this are starting to move things in the right direction, but we have a long way to go. Data is often treated as an afterthought. If you look at NeurIPS, arguably the most prestigious conference in our field, it’s been growing exponentially. Yet, in recent conferences, there were very few papers on datasets. Only last year did they add a “datasets and benchmarking” track. This is a problem.

We need to change how we think. We need to think about how we design datasets. Too often we find a dataset, or we scrape a dataset, or we take the data we have as given. How do we design them? Then, how do we create datasets that realize our designs?
In order to do this, we need to get better at measuring data quality. If you can’t measure it, you can’t improve it. If you ultimately want to create any good engineering product—it doesn’t matter whether it’s conventional software or a dataset—you need to be able to iteratively evolve it and make it better with each pass.
Because datasets are becoming larger and more complex as ML evolves, we also need to think about data efficiency. How do we create datasets that capture functionality in the least amount of data possible? We at MLCommons believe there is one key tool to changing how we think and beginning to solve these problems, and that is to focus on creating better public datasets.

Why do we feel public datasets are so important? Public datasets do two things really well. They enable researchers to overcome core technical issues. For instance, if you’re interested in a problem like testing a conversational AI solution or detecting out-of-distribution data, your ability to do that and reason about it is determined by your ability to have a great dataset.
They also help us solve specific, impactful problems. For instance, detecting various types of cancer. Public datasets fuel our ability to use research to do both of these critical things.
We’ve been very lucky over the last decade to have some extraordinary work on our initial public datasets. If you look at papers with code, you look at the highly cited datasets, you can see what an amazing impact these have had. You can argue that ImageNet was some of the best money we’ve ever spent—it was a few hundred thousand dollars to create that dataset. We literally fueled billions of dollars of research and, much more, and delivered industrial value off of that very small initial investment.

More than even a tool for doing research, public datasets are the language of ML research. Overwhelmingly, research papers cite public data, not private data. This is true even for the largest ML-focused companies like Meta, Google, or Microsoft. Datasets are the language we use to communicate the results of our ML research.

ML is evolving. We’ve had a great last decade, but we need to look forward to the decade ahead. We are rapidly exhausting existing data and test datasets. You can look at the progress made with natural language models attacking various problems. New test datasets come out, and they get solved faster and faster.
We’re discovering quality issues in existing test datasets. There’s some really great work by Curtis Northcutt and others analyzing ImageNet and issues in ImageNet—and this is one of the cornerstones of our field. We’re developing new classes of models, giant models, trained on extremely large unlabeled datasets, and then fine-tuned for specific tasks—these are a new thing, and they bring with them new challenges.

Multi-modal models are becoming increasingly important. We’re realizing just how critical it is to do our best to eliminate bias in data and be sensitive and responsible, legally and ethically, in how we source and use data.
As ML evolves, we need our public datasets to evolve with it. We need to ask ourselves, what public datasets will drive research for the next decade? What are going to be the datasets of 2030?

In order to answer that question, there are two critical questions. The first critical question is what research challenges do we want to attack? What things, if we can figure out how to do them, will keep us all better informed, will make us all more productive, will make us healthier, will make us safer? ML has the potential to do this if we continue to develop its capabilities.

Once we answer the question of what fundamental research challenges matter most, what datasets will we need to attack those challenges? How do we create truly difficult test sets that model all the nuance and challenge of important real-world problems and use those to drive higher model quality? How do we build, for instance, conversational test sets for giant language models? How do we train multi-modal models, and how do we do all of this while reducing bias and legally and ethically sourcing our data?

At MLCommons, we’re trying to help answer this question by bringing together a whole bunch of folks from different companies and academic institutions. We’ve created several really interesting datasets to date. Two I’m gonna talk about here were released last year. One is The People’s Speech. This is over 30,000 hours of transcribed English speech by diverse speakers under a very permissive license.
Another is the Multilingual Spoken Words Corpus. This is spoken words, as you can imagine, and has keywords in 50 different languages also under a permissive license. We’ve learned a lot in the process of building these datasets. In engineering, there’s no better way to truly understand the challenges of doing something than to go out and try and do it.
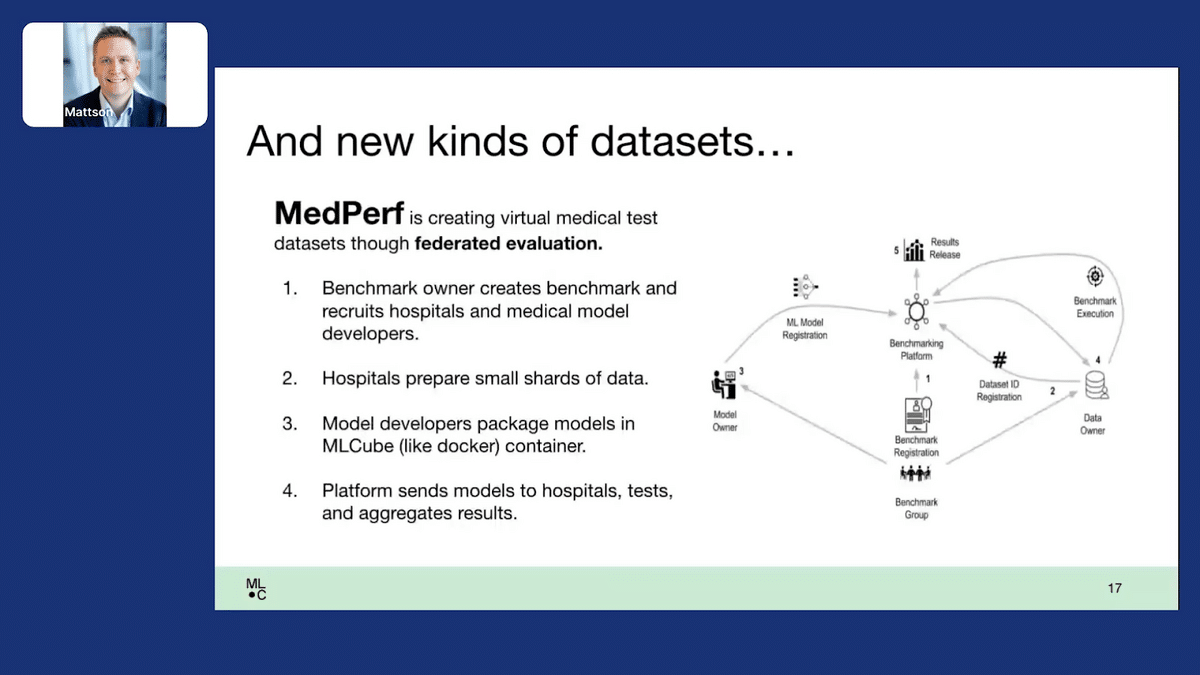
We’re also looking at creating new kinds of datasets because I believe that part of the way that we’re going to answer this question of what are the datasets for the next decade is to reimagine what a dataset is. One example of this is the MLCommons MedPerf project.
I think of MedPerf as creating a virtual medical test dataset. MedPerf basically takes the idea of federated evaluation, where you take a model that you think, based on your in-lab results, would be good for solving a particular healthcare problem. You would like to know if this will work for diverse patients in diverse clinical settings. What you do is you send the model out to a whole bunch of facilities, they securely evaluate it on private data and return only the results. Then, you aggregate those results and you get a much better idea of whether or not your model will do well in the wild and help patients. This is one example of rethinking what a dataset is. A bunch of data shards at different facilities serve the purpose of a common test dataset.

As we think about this problem of creating better datasets, whether it’s datasets within an organization for solving a particular purpose or public datasets to help the research community, there is one critical question we need to ask. What tools do we need to enable us to build these datasets and make them better?
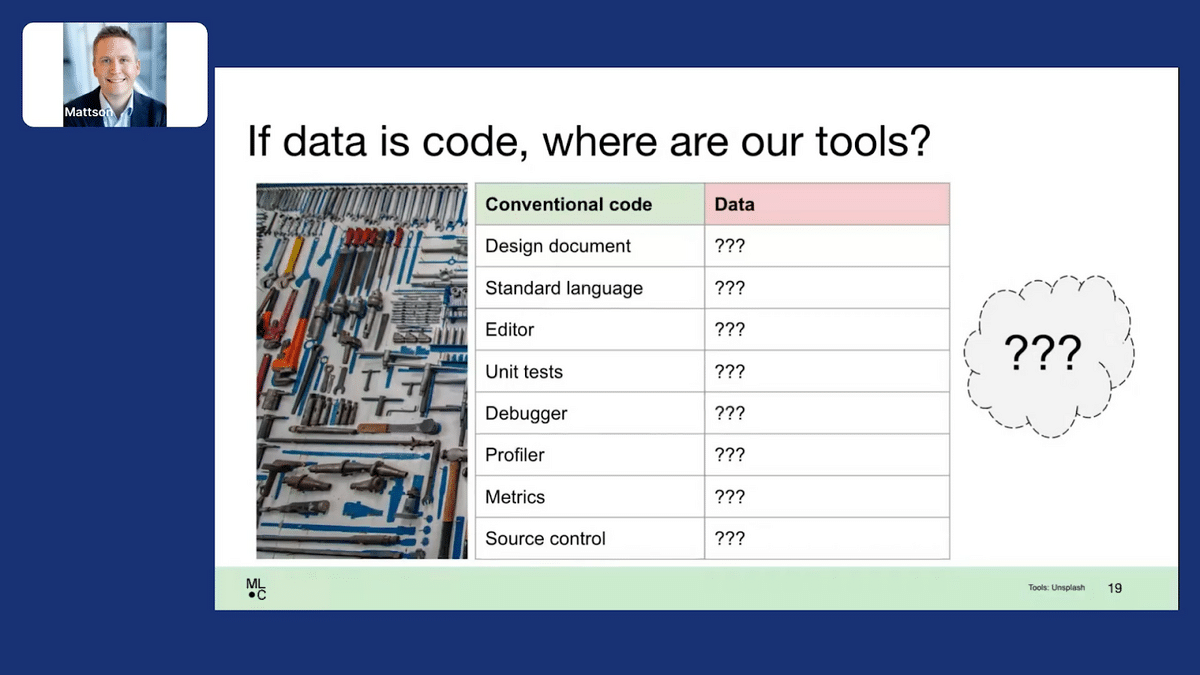
A useful way to think about this problem is that if data is code, where are the tools that we’re used to for conventional code? If you think about writing conventional code—I’m gonna create an application that does something—I might start with a design document, I know roughly what would be in that. I’ll pick a standard programming language that everyone else will understand. I’ll use an editor that’ll make me very productive. I will have unit tests to evaluate whether or not I’ve done it right. If I have a problem, I’ve got a debugger. Now I’m worried about speed, I’ve got a profiler. I’ll use different metrics to evaluate the response time of my application or different key qualities. As I go through this whole process, I’ll have access to source control that lets me track versions and work with others to try and build the result I want.
If you think about data, we have only the most primitive beginnings in some of these areas, and in others, we really have no idea what the equivalent tool is. I really hope that the attendees at this conference, the companies involved in this community, and organizations like MLCommons can come together and try and create the tools we all need to do better things with data.

Two examples of tools that we’re working on MLCommons. One is, on the metrics front, we introduced DataPerf. Just as we have very mature benchmarks for certain classes of models, we need benchmarks and leaderboards for data.

For instance, we need to be able to measure three things. We need to be able to measure how good a training dataset is because we want to learn how to build better ones. We want to learn how good a test set is because we want to create continuously improving test sets. That means getting more difficult and getting difficult as a result of better approximating real-world problems. Lastly, we want to build better algorithms for working with data—things that find errors or optimize datasets for efficiency.

To make this concrete, you could benchmark a training dataset by asking people to submit different training datasets, holding a set of models fixed, training the models on different training datasets, compositing the accuracy, and comparing the composite accuracy. What training datasets produce the most accurate models? You can learn a lot from doing that.
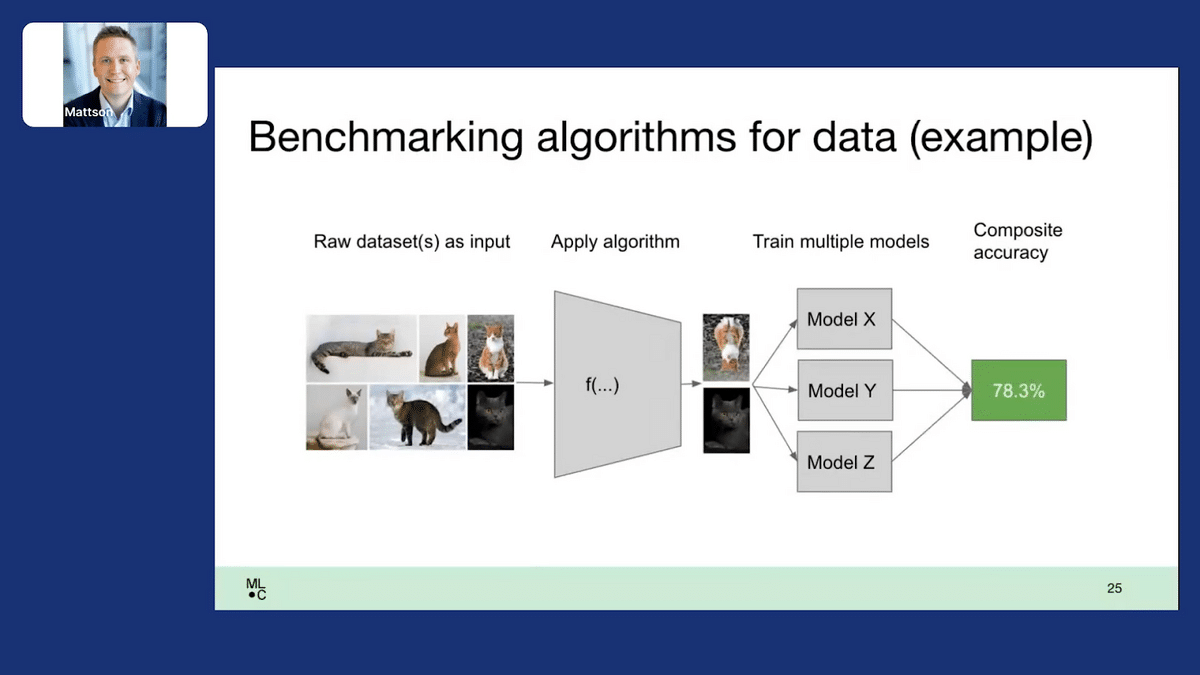
Similar idea with test data— you’re looking for specific datapoints or whole test datasets that models have trouble labeling and that humans label well, are not just a small corner case, are novel and well-distributed, and you’re looking to actually drive down the quality that a set of fixed models produced.
Algorithms are basically the transformative case of benchmarking training datasets. You apply a transformation to a fixed dataset, you’re hoping that transformation is good, and you see what effect it has on your fixed set of models. This is inverting the paradigm we’ve all gotten used to for model benchmarking—hold the dataset constant during the model. We hold the models constant and we vary the dataset in different ways.
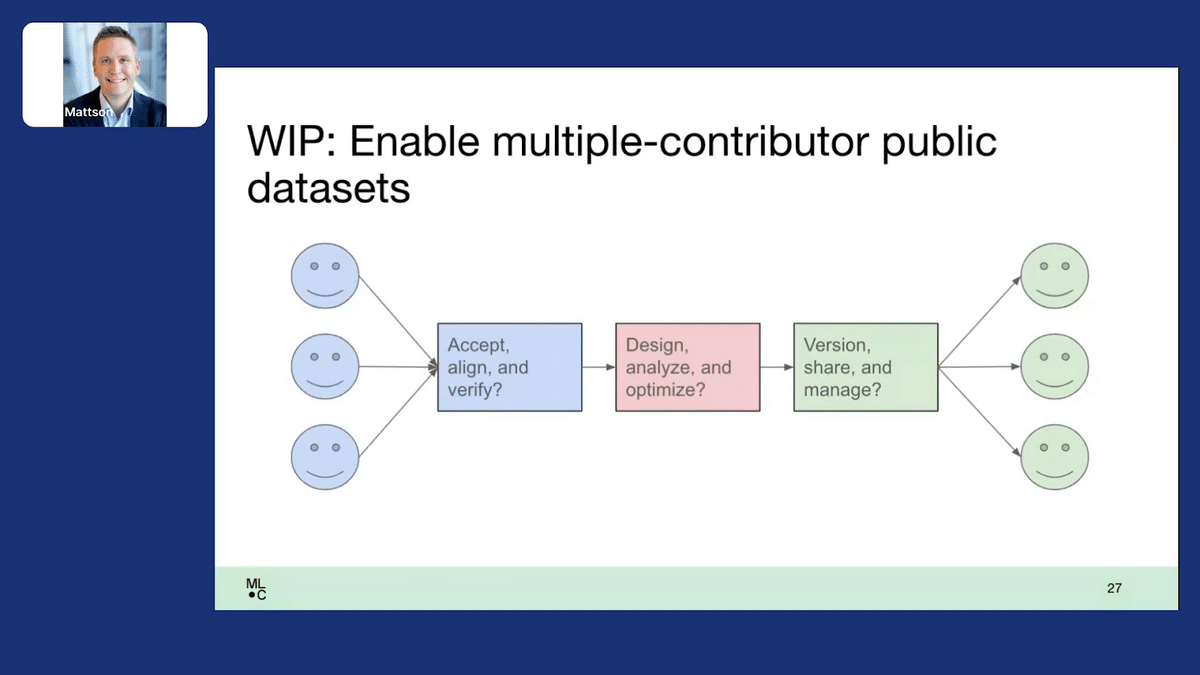
More recently, we’ve started to look at the challenge of source control. How do we bring together multiple contributors to create public datasets? How do we take in the data contributions from different sources, accept them, align them in terms of a common format, and verify their correctness? We don’t just want to pile up data. We’d like to design the dataset we’re all trying to work together to create, analyze the data we have, figure out what data we need and what data we can get rid of to make it more lean and efficient, and ultimately take this data, version it perhaps for different purposes, and share it among a broad community and manage issues as they arise.
If we can come together and do these things, we can create public datasets that, rather than being static assets as they’re all too often today, are living, evolving, common goods that help us all do better research and develop better products and services.
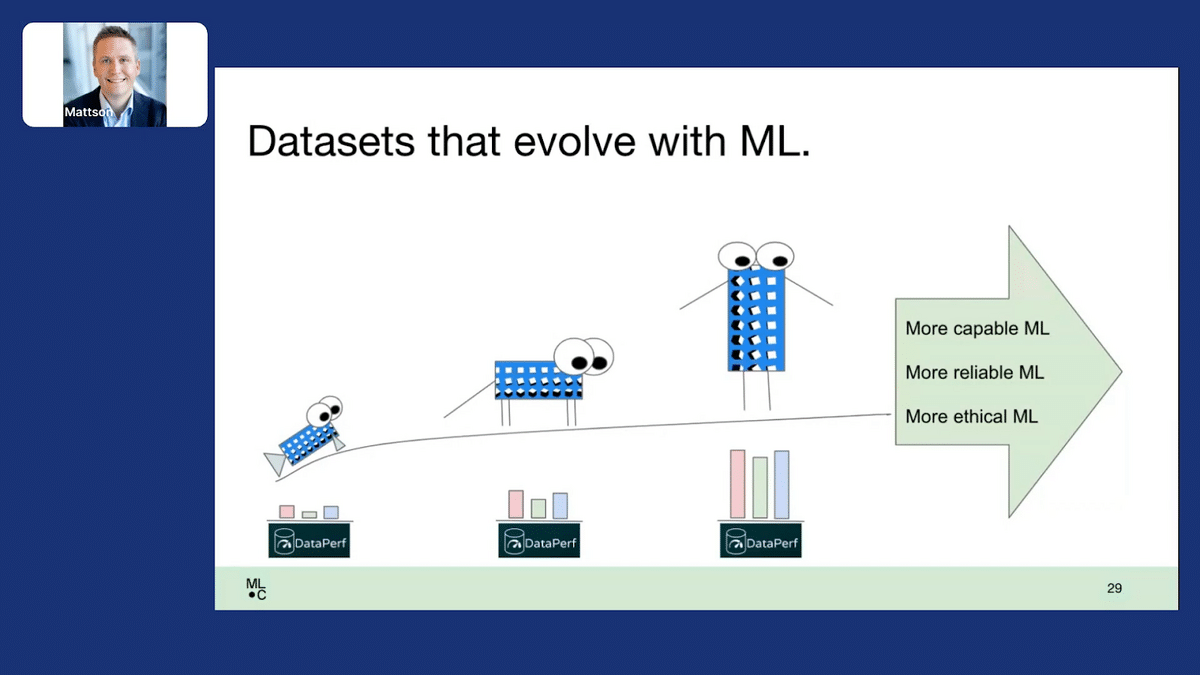
Why should we all care about this? We all have a common goal. If we can create datasets that evolve with ML, they’ll start small, and they’ll have problems, but over time they’ll become valuable research tools and ultimately common ways of doing important things. We can create more capable machine learning, more reliable machine learning, and more ethical machine learning, and track our progress using metrics so we know we’re getting there, and do things to solve problems that matter.

We can make people healthier. We can make people safer. We can give more people, no matter who they are or where they are, access to the information they need, and make us all more productive so we can live richer, more interesting lives. ML has tremendous potential. It’s all driven by data, and a lot of the most critical data is public data.
If we’re going to do this, we need to bring together more smart people. We have a wonderful group of people working on MLCommons. We’d love to get more participants. We’re a very open and welcoming organization. We’d love to see submissions to DataPerf. Help us drive the future of data, and if you have a great idea, seek us out at MLCommons—we’d love to help you realize it and move the community forward.

MLCommons Question and Answer section
Aarti Bagul: Thanks so much, Peter. That was a really amazing talk, and I think it brought together a bunch of threads we’d discussed earlier in the last two days of sessions.
The first question we have is, “In this conference, we learned that in the real world, the data is often drifting and label schema evolving. How do you really create public datasets that can keep up?”
Peter Mattson: I think the rate of data drift is highly problem sensitive. If you think about wanting to create a dataset for vision or for transcribing speech, your rate of data drift may be a lot slower than you might see in say, a commercial recommendation dataset. For those types of datasets, the problem is actually pretty static. It’s all about evolving the dataset to be better—evolving a training set that produces a better model, or evolving a test set that is a better definition of the problem that encourages everyone to make a better solution.
We do definitely need datasets that capture the idea of data drift and data evolution so that we can build technologies that help with those problems. That is a very real thing, especially in a commercial setting where the data evolves very quickly.
AB: Makes sense. Along those lines, Hassan asked, “Do you think that creating standards to ensure certain properties on datasets can be useful?” Are there certain standards that you’re already seeing that make good public datasets? Is that something that should be an overall standard for people creating?
PM: Absolutely, we need standards. We do have things like data cards out there for labeling data, but there are some very basic things that we don’t have. Even for common dataset types, there’s no widely recognized standard for just the format of the dataset. For the responsible AI standards, we need to be very careful to build a good ladder that enables people to, say starting out as researchers building a research dataset, to do basic responsible things and then slowly increase those responsibility standard compliance as their dataset grows in scope and importance.
I think we have a long way to go. There are definitely tool interoperability issues. We have almost an empty toolbox or a toolbox with some sticks and rocks in it. We take for granted a complex toolchain for writing code where everything interoperates.
AB: One last question. I’ve been wondering, for a while, developing and benchmarking models seems easy. You have a test set, you get a score, and you know if that’s a good model or not. How do you evaluate the quality of the data, like the training set example you gave? The training set, that’s best for this task would be the one that’s most similar to your test set maybe, or your validation set at least. So, how are you developing datasets, in terms of a general framework, in terms of evaluating the quality of the data? This seems much harder than just benchmarking models where you have a ground truth, i.e. the labels for this dataset. What does ground truth or even the test dataset look like for benchmarking data?
PM: I’m not sure that evaluating data or evaluating models is actually necessarily solved. What we all should start thinking about is evaluating solutions. We have real-world problems that we are trying to solve. The first step is that we approximate those real-world problems with a test set.
The better that test set gets… suppose you have a really accurate test set for safe driving, for recognizing stop signs, and so forth. By definition, creating a training set that happens to do well and conforms to that test set is creating a really good training set.
The whole trick is to figure out how to get your test set close to the real-world problem. Both in terms of breadth—making sure you’ve fully covered the scope you care about—and difficulty—depth, making sure that you have the really hard edge and corner cases well represented.
More Snorkel AI events coming!
Snorkel has more live online events coming. Look at our events page to sign up for research webinars, product overviews, and case studies.
If you're looking for more content immediately, check out our YouTube channel, where we keep recordings of our past webinars and online conferences.