phData, an Advanced AWS Consulting Partner and Elite Snowflake Consulting Partner (plus 2x partner of the year!), provides expert end-to-end services for machine learning and data analytics. phData Senior ML Engineer Ryan Gooch recently evaluated options to accelerate ML model deployment with Snorkel Flow and AWS SageMaker.
The manufacturing industry has experienced a massive influx of data due to both digitization and the rise of IoT and telemetry technologies. However, there are significant obstacles to making that data actionable. While innovative manufacturers harness significant value with data and analytics, AI, and machine learning, many of the most ambitious AI projects remain stuck in pilot purgatory.
At phData, we help manufacturers and other companies seamlessly collect, manage, and act upon massive amounts of data to transform how they do business. Whether it’s creating real-time reporting on manufacturing output, constructing sophisticated data engineering pipelines, architecting robust MLOps solutions, or building models to help predict when to perform maintenance, we empower leading manufacturers to bring ambitious data and analytics projects to life.
Over the past year, we’ve seen manufacturers explore a host of techniques and tools aimed at making AI data development practical and possible under the umbrella of “data-centric AI.” In many cases, machine learning (ML) teams tap research-based and industry-proven startups like Snorkel AI to capitalize on cutting-edge techniques and integrate this technology with trusted, mature enterprise platforms to build AI solutions they can operationalize at scale.
AI offers use cases across every aspect of the manufacturing business.
In this post, we will detail how a manufacturer with an extensive dealer network could use AI to empower its dealers to deliver a superior experience for their end-users. This involves developing and tuning a model customized to extract rich insights from invoices using Snorkel’s data development platform and deploying with AWS Sagemaker.
Manufacturing Solutions
For the best possible customer experience, heavy equipment manufacturers want to ensure as little equipment downtime as possible. Complex and intermittent equipment issues, scattered service records, and the unique design of each vehicle can make quick and accurate issue resolution a challenge.
What if every time a piece of equipment was taken in for service, exactly the right parts—from the complex and bespoke to nuts and bolts—arrived and ready for installation exactly on time? Data scientists can train machine learning models to predict categories of service needs, and then downstream models can precisely diagnose an issue and suggest remediation along with each part required.
However, the success of any predictive system hinges upon having a sufficient quality (and quantity) of example data representing the myriad issues and solutions complex heavy equipment might face.
The traditional approach: brittle rules-based systems
Developing and curating datasets for machine learning applications can be an extremely labor-intensive task. Modeling teams charge ahead without data-centric tooling and build a vast array of SQL-based rules to attempt to capture all of the permutations of equipment and service needs.
Each new product launch breaks the system, and developers might spend months catching up. If a new modeling approach or new category of service needs is proposed, everything goes back to the drawing board.
Many teams have experimented with off-the-shelf large language models (LLMs), but these lack domain-specific information and terminology critical to understanding the heavy equipment space and the nuances of specific parts.
The alternative: programmatic data development with Snorkel Flow
Snorkel takes a data-centric approach to complex document and image classification challenges. The Snorkel Flow AI data development platform provides a comprehensive, iterative method for machine learning teams to start with a commercial or open-source LLM, identify subsets of data where the model makes errors, and correct those errors via programmatic data development.
Snorkel Flow enables machine learning teams to collaborate with internal experts to develop data operators that perform labeling, filtering, and sampling operations as code functions. These labeling functions can be written quickly, applied to large volumes of data, and inspected, weighted, and optimized.
Ultimately teams can rapidly generate high-quality data sets, fine-tune an existing model, or distill an LLM to a smaller, specialized model with reduced training and inference costs.
Building and deploying production-quality AI solutions with AWS and Snorkel
In the example above, the data science team would need to start with access to dealer invoices. The easiest approach is to have PDFs of scanned invoices in Amazon S3.
The Snorkel Flow platform integrates natively with AWS to make this data available with a few clicks. The data scientist simply selects “AWS S3” as a data source when creating a new dataset in Snorkel Flow and then enters the appropriate connection details and credentials. All credentials are encrypted end-to-end, which ensures that sensitive credentials are never exposed.
Snorkel Flow has a customized AWS Textract document model that provides a method for extracting not only text in documents but also honors tabular structures inherent in structured forms. Relevant data, splits, and identifiers are recognized, allowing Snorkel Flow to ingest the dataset, making it immediately referenceable throughout the platform.
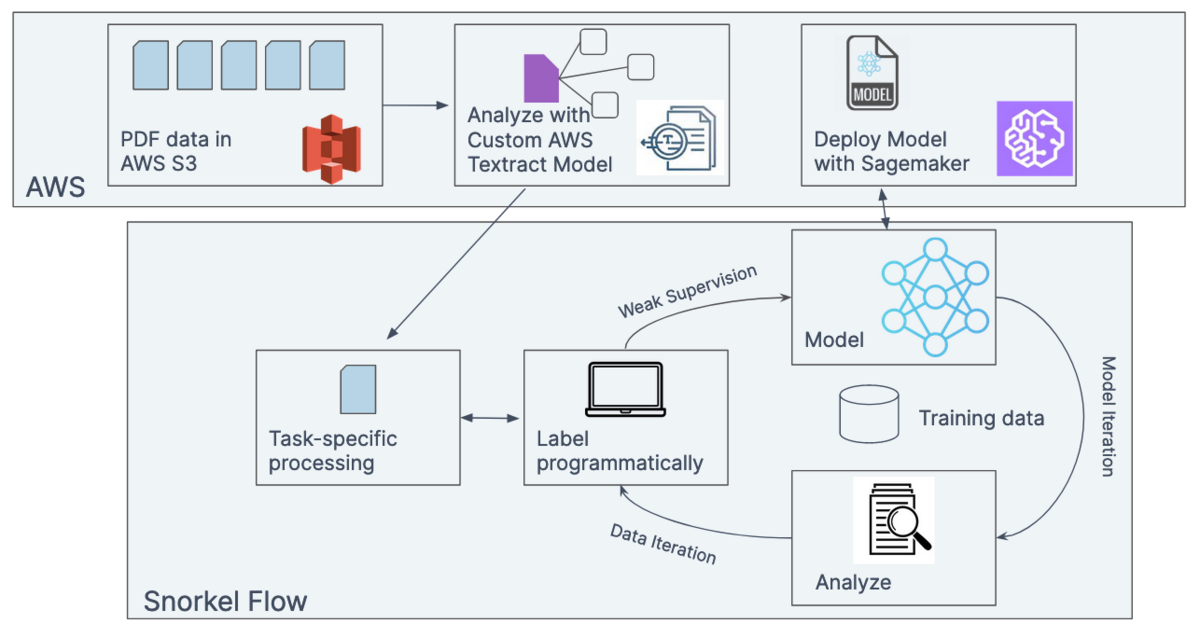
Figure. Invoices are ingested into S3. For raw PDFs, AWS Textract can be used to pull specific fields and text out of invoices for database insertion.
In a typical workflow, users initially select a foundation model (FM) via a platform like AWS SageMaker Jumpstart and then construct a generic prompt. The output of the prompt acts as the baseline for further development. As the user identifies areas where the FM underperforms or makes errors, they employ programmatic data development to make corrections. The data science team collaborates with heavy-equipment experts to efficiently codify expertise buried in service reports. They may also adjust the data mixture by sampling, filtering, or even adding new data via augmentation or synthetic data generation.
When complete, the team can use Snorkel Flow to export a high-quality data set, fine-tune an LLM, or distill a much smaller, specialized model with drastically lower training and inference costs.
Deploying models trained in Snorkel Flow with SageMaker
AWS SageMaker is the go-to machine learning platform for many data science teams. This fully managed service brings together a broad set of tools to enable high-performance ML for a broad variety of use cases. Sagemaker makes it easy to deploy ML models at scale, with reduced inference cost and the ability to manage models effectively in production. SageMaker also offers access to hundreds of pre-trained models, including publicly available FMs via Sagemaker Jumpstart.
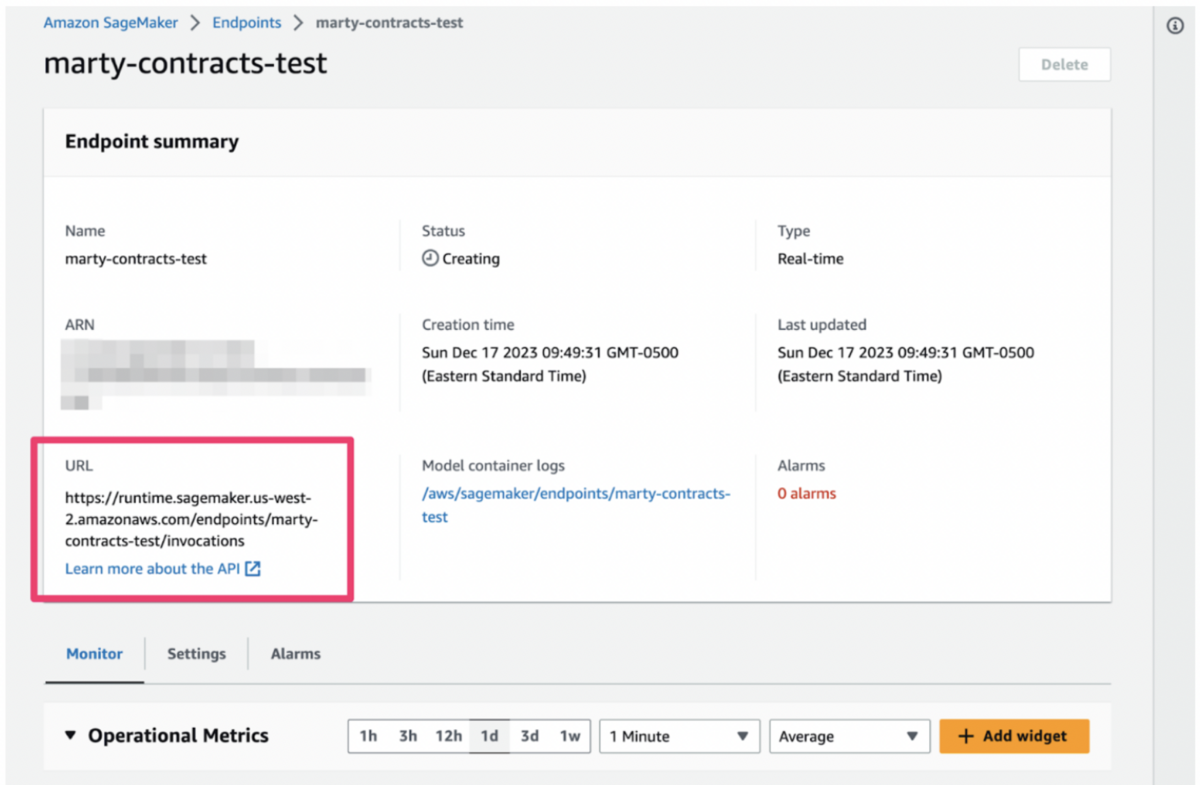
Models trained in Snorkel Flow are MLflow-ready and can easily be deployed using AWS SageMaker. The first step is to export a model trained using Snorkel Flow as a zip file to a local machine. You need to create a containerized runtime environment for your MLflow deployment and push this environment to Amazon ECR. After creating the container environment, push the model objects to the AWS SageMaker model registry.
From AWS SageMaker, you can view the newly created model entry. Now that the container environment and model object exist, they can be combined and deployed as an AWS SageMaker endpoint or batch transform job.
AWS SageMaker inference types should be configured based on business needs, required production inference volumes, desired latency, etc.
To deploy the model to a SageMaker endpoint:
- Create a new endpoint configuration or use an existing configuration. The screenshot below uses SageMaker’s default endpoint configuration settings.
- Create the endpoint.
- Test model inference according to the inference type that you specified in the endpoint configuration. The base configuration uses MLflow’s native /invocations REST API endpoint. See the MLflow documentation for more information about the MLflow API specs
Snorkel AI + SageMaker: efficiently solving problems
This manufacturing use case serves as a great example of the potential of data-centric approaches to revolutionize industry practices.
By leveraging Snorkel Flow’s innovative data curation platform, heavy equipment manufacturers can rapidly prototype and iterate on data labeling functions, enabling the creation of rich training datasets that accurately reflect the complexities of real-world applications and flexibly adapt and scale with the business. SageMaker JumpStart offers a seamless pathway to both developing these datasets, with pre-trained models acting as labelers, and rapidly deploying scalable solutions.
Want to learn more about what data-centric AI could do for your business?
Schedule a free workshop with phData to dive in.