

The Weather Company enhances MLOps with Amazon SageMaker, AWS CloudFormation, and Amazon CloudWatch
AWS Machine Learning Blog
JULY 8, 2024
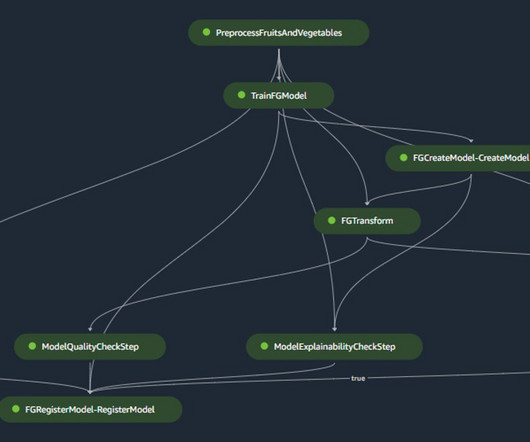
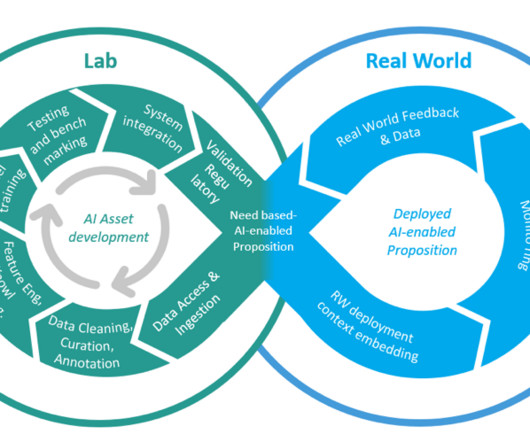
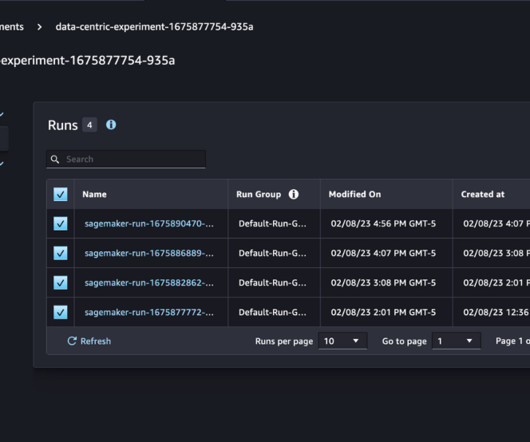
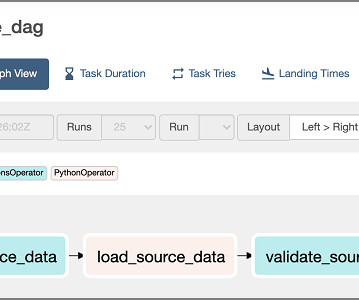
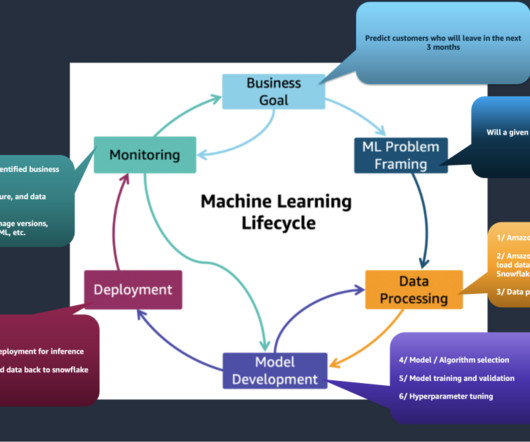
TWCo data scientists and ML engineers took advantage of automation, detailed experiment tracking, integrated training, and deployment pipelines to help scale MLOps effectively. The Data Quality Check part of the pipeline creates baseline statistics for the monitoring task in the inference pipeline.


































Let's personalize your content