

Enhancing healthcare documentation with IDP
AI News
SEPTEMBER 26, 2024
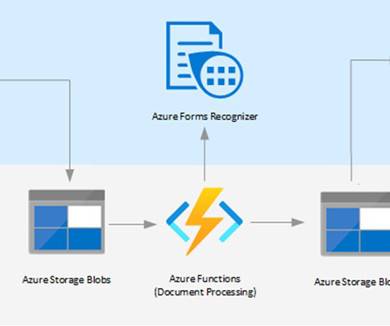
Healthcare documentation is an integral part of the sector that ensures the delivery of high-quality care and maintains the continuity of patient information. With the advent of intelligent document processing technology, a new solution can now be implemented.














































Let's personalize your content