
This AI Paper Introduces A Comprehensive RDF Dataset With Over 26 Billion Triples Covering Scholarly Data Across All Scientific Disciplines
Marktechpost
AUGUST 19, 2023
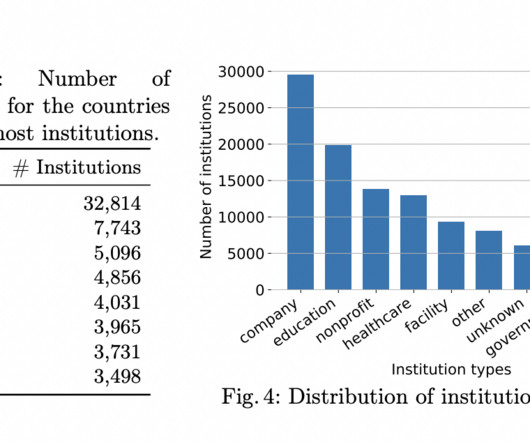
Modeling the underlying academic data as an RDF knowledge graph (KG) is one efficient method. This makes standardization, visualization, and interlinking with Linked Data resources easier. As a result, scholarly KGs are essential for converting document-centric academic material into linked and automatable knowledge structures.








Let's personalize your content