Mistral’s New Model Crushes Benchmarks in 4+ Languages
Analytics Vidhya
APRIL 21, 2024
Mixtral 8x22B by Mistral AI Crushes Benchmarks in 4+ Languages The post Mistral’s New Model Crushes Benchmarks in 4+ Languages appeared first on Analytics Vidhya.

Analytics Vidhya
APRIL 21, 2024
Mixtral 8x22B by Mistral AI Crushes Benchmarks in 4+ Languages The post Mistral’s New Model Crushes Benchmarks in 4+ Languages appeared first on Analytics Vidhya.

AI News
APRIL 17, 2024
SAS, a specialist in data and AI solutions, has unveiled what it describes as a “game-changing approach” for organisations to tackle business challenges head-on. Introducing lightweight, industry-specific AI models for individual licence, SAS hopes to equip organisations with readily deployable AI technology to productionise real-world use cases with unparalleled efficiency.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Unite.AI
APRIL 13, 2024
The use of AI in marketing has changed how businesses communicate with clients. It provides personalized client experiences and can automate repetitive tasks. According to a McKinsey study , around 75% of the value AI use cases could deliver falls across four areas, and marketing is one of these. The Artificial Intelligence (AI) in marketing size is expected to reach $145.42 billion by 2032.

IBM Journey to AI blog
APRIL 22, 2024
AI can be a force for good, but it might also lead to environmental and sustainability concerns. IBM is dedicated to the responsible development and deployment of this technology, which can enable our clients to meet their sustainability goals. “AI is an unbelievable opportunity to address some of the world’s most pressing challenges in health care, manufacturing, climate change and more,” said Christina Shim, IBM’s global head of Sustainability Software and an AI Ethics

Speaker: Conrado Morlan
In this engaging and witty talk, we’ll explore how artificial intelligence can transform the daily tasks of product managers into streamlined, efficient processes. Using the lens of a superhero narrative, we’ll uncover how AI can be the ultimate sidekick, aiding in decision-making, enhancing productivity, and boosting innovation. Attendees will leave with practical tools and actionable insights, motivated to embrace AI and leverage its potential in their work. 🦸 🏢 Key objectives:


Marktechpost
APRIL 30, 2024
Extracting information quickly and efficiently from websites and digital documents is crucial for businesses, researchers, and developers. They require specific data from various online sources to analyze trends, monitor competitors, or gather insights for strategic decisions. Collecting this data can be time-consuming and prone to errors, presenting a significant challenge in data-driven industries.
Artificial Intelligence Zone brings together the best content for AI and ML professionals from the widest variety of thought leaders.

Analytics Vidhya
APRIL 5, 2024
Introduction Python is the magic key to building adaptable machines! Known for its beginner-friendliness, you can dive into AI without complex code. Python’s superpower? A massive community with libraries for machine learning, sleek app development, data analysis, cybersecurity, and more. This flexible language has you covered for all things AI and beyond.

AI News
APRIL 15, 2024
OpenAI has announced the opening of a new office in Tokyo to drive its expansion into the Asian market. The new office aims to foster collaboration with the Japanese government, local businesses, and research institutions to develop AI tools tailored to Japan’s unique requirements. Tokyo was selected for OpenAI’s first Asian venture due to its global leadership in technology, a culture dedicated to service, and an innovative community. “We’re excited to be in Japan which

NVIDIA
APRIL 24, 2024
To help customers make more efficient use of their AI computing resources, NVIDIA today announced it has entered into a definitive agreement to acquire Run:ai, a Kubernetes-based workload management and orchestration software provider. Customer AI deployments are becoming increasingly complex, with workloads distributed across cloud, edge and on-premises data center infrastructure.

IBM Journey to AI blog
APRIL 19, 2024
This blog series discusses the complex tasks energy utility companies face as they shift to holistic grid asset management to manage through the energy transition. Earlier posts in this series addressed the challenges of the energy transition with holistic grid asset management, the integrated asset management platform and data exchange, and merging traditional top-down and bottom-up planning processes.

Advertisement
The complexity of financial data, the need for real-time insight, and the demand for user-friendly visualizations can seem daunting when it comes to analytics - but there is an easier way. With Logi Symphony, we aim to turn these challenges into opportunities. Our platform empowers you to seamlessly integrate advanced data analytics, generative AI, data visualization, and pixel-perfect reporting into your applications, transforming raw data into actionable insights.

Marktechpost
APRIL 29, 2024
With the significant development in the rapidly developing field of Artificial Intelligence driven healthcare, a team of researchers has introduced OpenBioLLM-Llama3-70B & 8B models. These state-of-the-art Large Language Models (LLMs) have the potential to completely transform medical natural language processing (NLP) by establishing new standards for functionality and performance in the biomedical field.

SAS Software
APRIL 5, 2024
Authors: Steven Harenberg and Amy Becker The total solar eclipse taking place across a thin band of the United States on April 8, 2024, is going to be a stellar event. In this post, we will help plan a journey to see the total solar eclipse. We will use algorithms [.] The post Planning your solar eclipse journey with network analytics appeared first on SAS Blogs.

Analytics Vidhya
APRIL 22, 2024
Introduction In natural language processing (NLP), it is important to understand and effectively process sequential data. Long Short-Term Memory (LSTM) models have emerged as a powerful tool for tackling this challenge. They offer the capability to capture both short-term nuances and long-term dependencies within sequences. Before delving into the intricacies of LSTM language translation models, […] The post Language Translation Using LSTM appeared first on Analytics Vidhya.

Explosion
APRIL 4, 2024
With the latest advancements in NLP and LLMs, and big companies like OpenAI dominating the space, many people wonder: Are we heading further into a black box era with larger and larger models, obscured behind APIs controlled by big tech monopolies?

Speaker: Gary Dmitriev
Our upcoming webinar aims to demystify the process of selecting and implementing automation tools for financial institutes. This session will provide your roadmap for vetting potential solutions, focusing on due diligence, vendor assessments, and aligning technology with strategic goals. We’ll also address the critical issue of innovation fatigue, offering tips on maintaining enthusiasm and momentum for new initiatives.

NVIDIA
APRIL 23, 2024
NVIDIA announced today its acceleration of Microsoft’s new Phi-3 Mini open language model with NVIDIA TensorRT-LLM , an open-source library for optimizing large language model inference when running on NVIDIA GPUs from PC to cloud. Phi-3 Mini packs the capability of 10x larger models and is licensed for both research and broad commercial usage, advancing Phi-2 from its research-only roots.

IBM Journey to AI blog
APRIL 15, 2024
The manufacturing industry is in an unenviable position. Facing a constant onslaught of cost pressures, supply chain volatility and disruptive technologies like 3D printing and IoT. The industry must continually optimize process, improve efficiency, and improve overall equipment effectiveness. At the same time, there is this huge sustainability and energy transition wave.

Marktechpost
APRIL 7, 2024
In the data management and retrieval landscape, vector databases have emerged as a revolutionary force, transforming how businesses and tech enthusiasts harness the power of complex, high-dimensional data. Let’s delve into the intricacies of vector databases, shedding light on their real-world applications and their profound impact on various industries.

Extreme Tech
APRIL 6, 2024
Semiconductors are at the heart of most electronics, but have you ever wondered how they work? In this article, we explain what semiconductors are, how they work, and just how tiny those transistors can get.

Speaker: Maher Hanafi, VP of Engineering at Betterworks & Tony Karrer, CTO at Aggregage
Executive leaders and board members are pushing their teams to adopt Generative AI to gain a competitive edge, save money, and otherwise take advantage of the promise of this new era of artificial intelligence. There's no question that it is challenging to figure out where to focus and how to advance when it’s a new field that is evolving everyday. 💡 This new webinar featuring Maher Hanafi, VP of Engineering at Betterworks, will explore a practical framework to transform Generative AI pr

Analytics Vidhya
APRIL 19, 2024
Meta introduces Meta AI, powered by the cutting-edge Llama 3, revolutionizing assistance across its platforms. With seamless integration and enhanced features, Meta AI aims to redefine user experiences. Let’s explore the features and applications of Meta’s AI assistant. Also Read: Meta Releases Much-Awaited Llama 3 Model Enhanced Assistance Everywhere Meta AI, leveraging Meta Llama 3, […] The post Meta AI: Your New Intelligent Assistant Powered by Llama 3 appeared first on Anal

Towards AI
APRIL 7, 2024
Author(s): Juliusnyambok Originally published on Towards AI. Building an End-to-End Machine Learning Project to Reduce Delays in Aggressive Cancer Care. After years of battling over control of the TV (sparked by my sister’s questionable obsession with true crime), my sister, the brilliant pharmacist Miss Nyambok Cynthia, and I decided to put our eternal sibling rivalry to good use.

NVIDIA
APRIL 22, 2024
Whether they’re monitoring miniscule insects or delivering insights from satellites in space, NVIDIA-accelerated startups are making every day Earth Day. Sustainable Futures, an initiative within the NVIDIA Inception program for cutting-edge startups, is supporting 750+ companies globally focused on agriculture, carbon capture, clean energy, climate and weather, environmental analysis, green computing, sustainable infrastructure and waste management.

AWS Machine Learning Blog
APRIL 16, 2024
Generative artificial intelligence (AI) is transforming the customer experience in industries across the globe. Customers are building generative AI applications using large language models (LLMs) and other foundation models (FMs), which enhance customer experiences, transform operations, improve employee productivity, and create new revenue channels.

Advertisement
Learn how to optimize email deliverability and drive greater email ROI. What lands your email in the customer’s inbox? Understanding those factors, otherwise known as email deliverability, is critical to getting the most return on your campaign investments. But the “rules” around which factors land you in the spam folder aren’t always easy to keep up with.
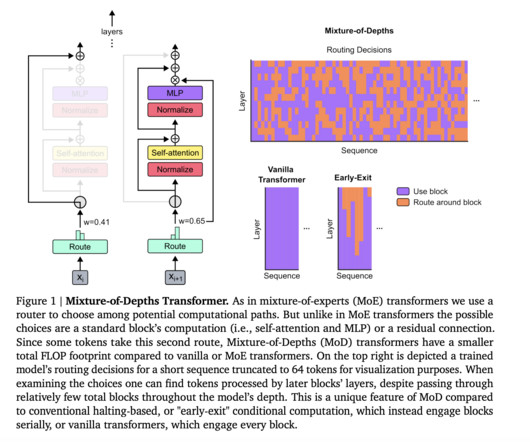
Marktechpost
APRIL 6, 2024
The transformer model has emerged as a cornerstone technology in AI, revolutionizing tasks such as language processing and machine translation. These models allocate computational resources uniformly across input sequences, a method that, while straightforward, overlooks the nuanced variability in the computational demands of different parts of the data.
Artificial Lawyer
APRIL 28, 2024
For many years there have been efforts to create an easy to use, reliable and affordable legal AI system that will give people advice and even draft documents for them.

Analytics Vidhya
APRIL 27, 2024
Introduction In today’s rapidly evolving world, the term ‘Generative AI’ is on everyone’s lips. Studies reveal that Generative AI is becoming indispensable in the workplace, with the market projected to reach $1.3 trillion by 2032. If you’ve been considering a career transition from a non-tech field to Generative AI, now is the time!

Towards AI
APRIL 10, 2024
Last Updated on April 11, 2024 by Editorial Team Author(s): ronilpatil Originally published on Towards AI. Image by Author Hi folks! Ready to take your model deployment game to the next level? Let’s dive into setting up an MLflow Server on an EC2 instance! I’ll explain the steps to configure Amazon S3 bucket to store the artifacts, Amazon RDS (Postgres & Mysql) to store metadata, and EC2 instance to host the mlflow server.

Speaker: Jay Black, Senior Account Executive
Let's set the record straight: in-store retail isn't dead - it's evolving! Faced with the digital age and the demands of omnichannel shopping, some retailers are thriving while others are struggling to adapt. Join Jay Black in this exclusive session as he explores the strategies that set successful stores apart, including: Crafting unique and unforgettable in-store experiences 🛍️ Mastering the art of retail demands 🛒 Navigating inventory challenges in today's climate 📦 an

NVIDIA
APRIL 24, 2024
To address the shift to electric vehicles, increased semiconductor demand, manufacturing onshoring, and ambitions for greater sustainability, manufacturers are investing in new factory developments and re-engineering their existing facilities. These projects often run over budget and schedule, due to complex and manual planning processes, legacy technology infrastructure, and disconnected tools, data and teams.

Microsoft AI
APRIL 30, 2024
Indonesia's eFishery built an AI copilot on Azure OpenAI Service to help fish and shrimp farmers achieve higher yields, more sustainably.

Marktechpost
APRIL 7, 2024
Machine Learning Operations (MLOps) refer to the set of practices for enhanced communication and collaboration during a machine learning project lifecycle. It involves principles like dataset validation, collaborative culture, application monitoring, reproducibility, etc., and ensures faster deployment, improved productivity, and reliability. With the rapid advancements in machine learning (ML), there has been an increase in the demand for MLOps specialists as well.

Expert insights. Personalized for you.






Let's personalize your content