
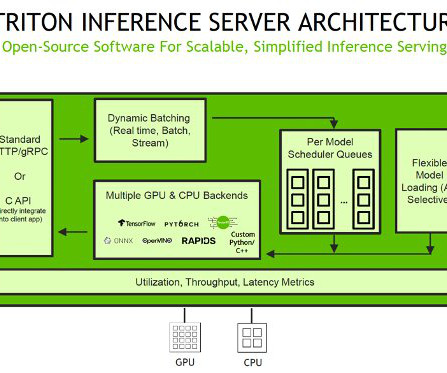
Host ML models on Amazon SageMaker using Triton: TensorRT models
AWS Machine Learning Blog
MAY 8, 2023
TensorRT supports major deep learning frameworks and includes a high-performance deep learning inference optimizer and runtime that delivers low latency, high-throughput inference for AI applications. With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization.






Let's personalize your content