

This AI newsletter is all you need #96
Towards AI
APRIL 23, 2024
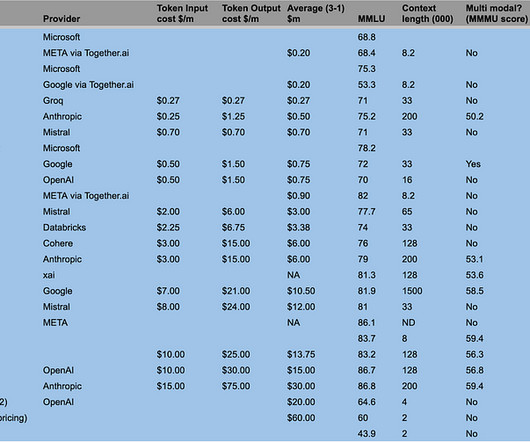
The breakthrough is huge jumps in model capabilities and benchmark scores for small model formats (8bn and 70bn parameters) and huge jumps in capabilities of the best open-source models. When choosing the best LLM for your application, there are many trade-offs and priorities to choose between. Why should you care? OpenAI or DIY?















Let's personalize your content