
Host ML models on Amazon SageMaker using Triton: TensorRT models
AWS Machine Learning Blog
MAY 8, 2023
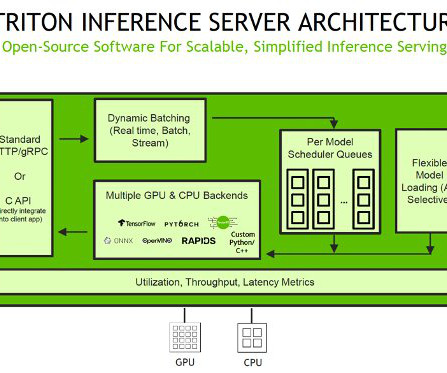
With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization. Additionally, TensorRT employs CUDA streams to enable parallel processing of models, further improving GPU utilization and performance. Set up the environment We begin by setting up the required environment.






Let's personalize your content