
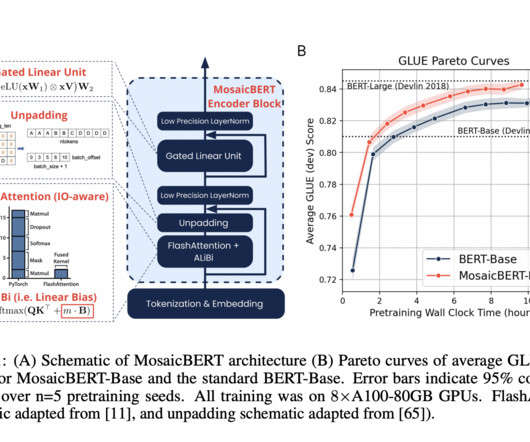
Meet MosaicBERT: A BERT-Style Encoder Architecture and Training Recipe that is Empirically Optimized for Fast Pretraining
Marktechpost
JANUARY 10, 2024
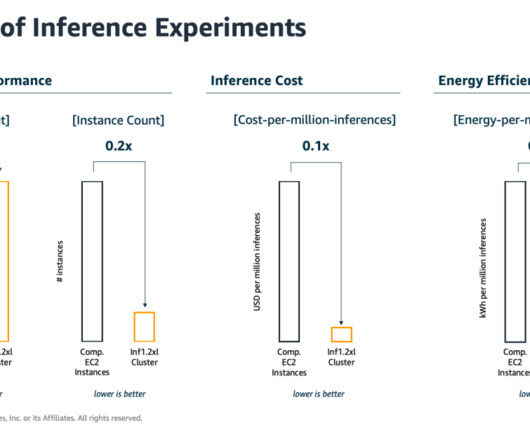
BERT is a language model which was released by Google in 2018. However, in the past half a decade, many significant advancements have been made with other types of architectures and training configurations that have yet to be incorporated into BERT. BERT-Base reached an average GLUE score of 83.2% hours compared to 23.35






















Let's personalize your content