

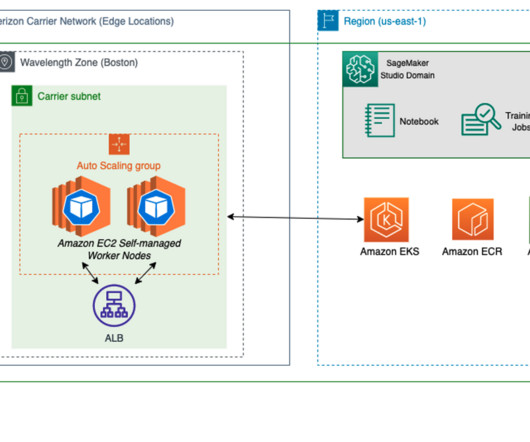
Deploy pre-trained models on AWS Wavelength with 5G edge using Amazon SageMaker JumpStart
AWS Machine Learning Blog
APRIL 7, 2023
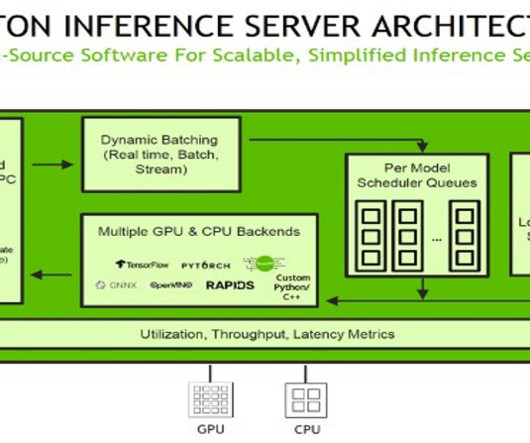
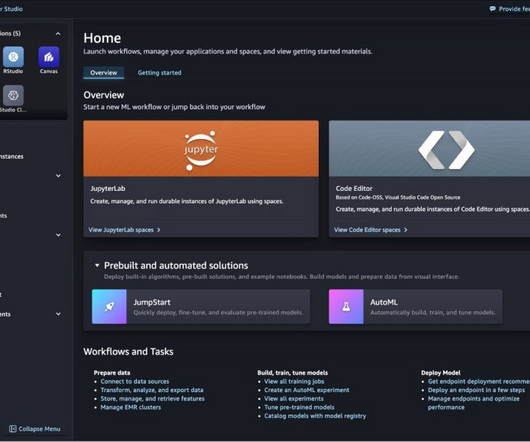
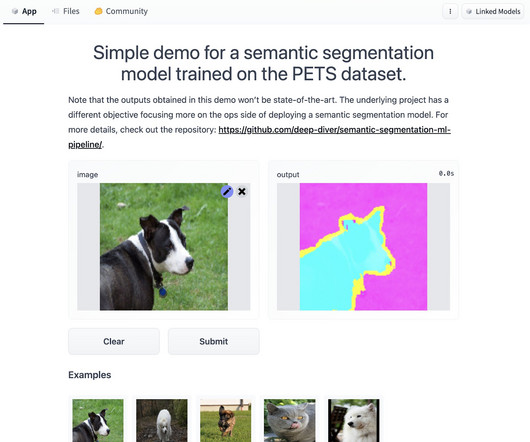
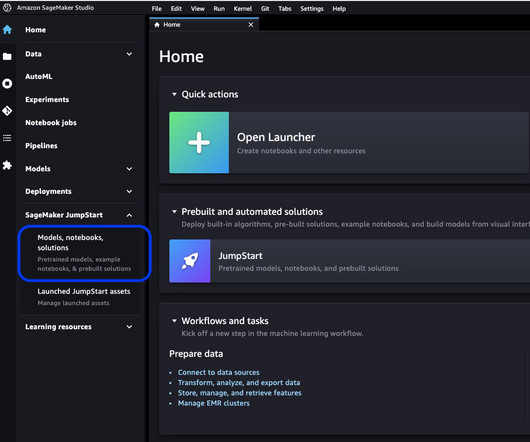
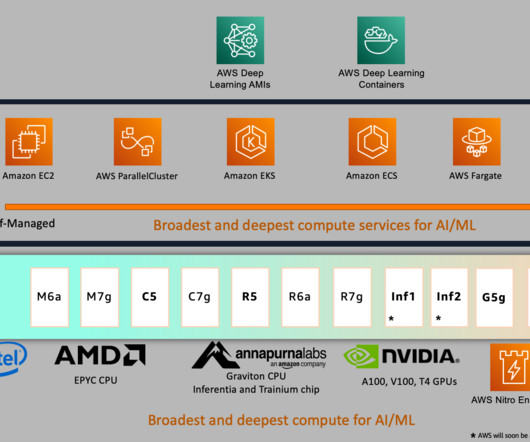
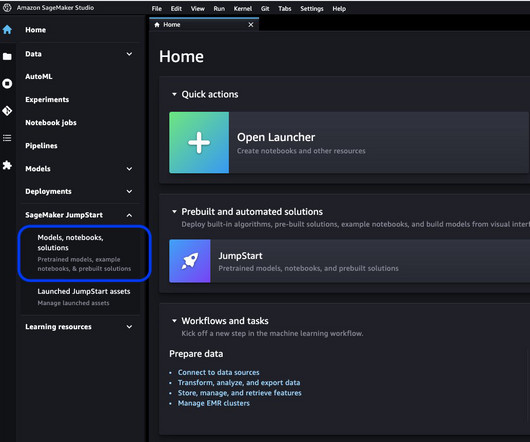
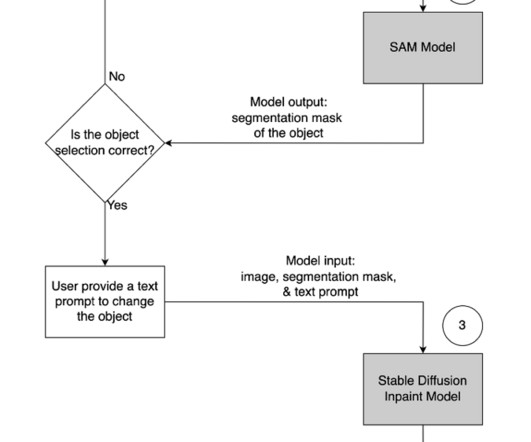
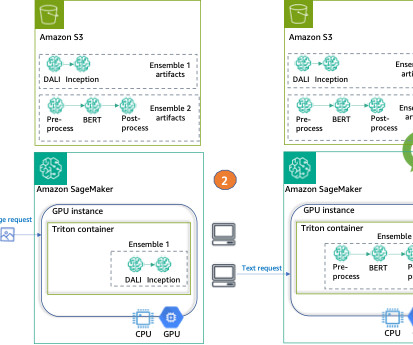
As one of the most prominent use cases to date, machine learning (ML) at the edge has allowed enterprises to deploy ML models closer to their end-customers to reduce latency and increase responsiveness of their applications. As our sample workload, we deploy a pre-trained model from Amazon SageMaker JumpStart.




















Let's personalize your content