


Clustering with Scikit-Learn: a Gentle Introduction
Towards AI
FEBRUARY 23, 2024
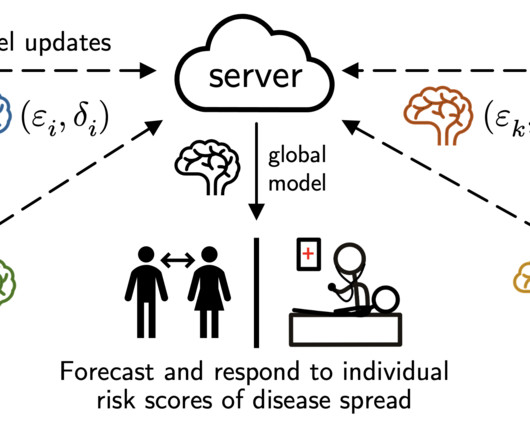
Learn how to apply state-of-the-art clustering algorithms efficiently and boost your machine-learning skills.Image source: unsplash.com. I will present the theory of the most used clustering models, and we will understand how to practically implement them with Scikit-Learn. As… Read the full blog for free on Medium.



























Let's personalize your content