LLM Inference Performance Engineering: Best Practices
databricks
OCTOBER 12, 2023
In this blog post, the MosaicML engineering team shares best practices for how to capitalize on popular open source large language models (LLMs).

 llm-inference-performance-engineering-best-practices Blog Related Topics
llm-inference-performance-engineering-best-practices Blog Related Topics 
databricks
OCTOBER 12, 2023
In this blog post, the MosaicML engineering team shares best practices for how to capitalize on popular open source large language models (LLMs).
AWS Machine Learning Blog
MAY 9, 2024
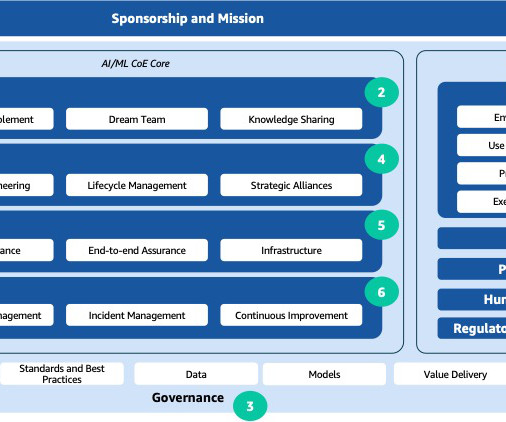
They establish and enforce best practices encompassing design, development, processes, and governance operations, thereby mitigating risks and making sure robust business, technical, and governance frameworks are consistently upheld.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
TheSequence
MARCH 11, 2024
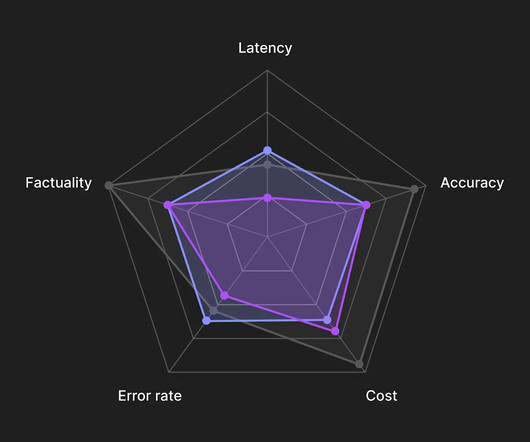
To successfully build an AI application, evaluating the performance of large language models (LLMs) is crucial. Given the inherent novelty and complexities surrounding LLMs, this poses a unique challenge for most companies. Today, Peter shares his insights on LLM evaluations.
AWS Machine Learning Blog
OCTOBER 6, 2023
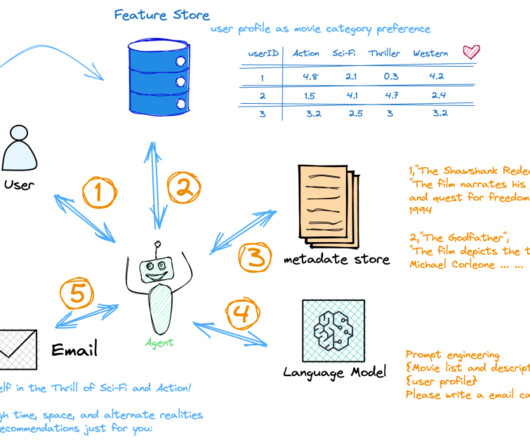
Large language models (LLMs) are revolutionizing fields like search engines, natural language processing (NLP), healthcare, robotics, and code generation. The personalization of LLM applications can be achieved by incorporating up-to-date user information, which typically involves integrating several components.
Heartbeat
JANUARY 9, 2024
The smooth deployment, continuous monitoring, and effective maintenance of LLMs within production systems are major concerns in the field of LLMOps. Solving these concerns entails creating procedures and techniques to guarantee that these potent language models perform as intended and provide accurate results in practical applications.
Bugra Akyildiz
APRIL 20, 2024
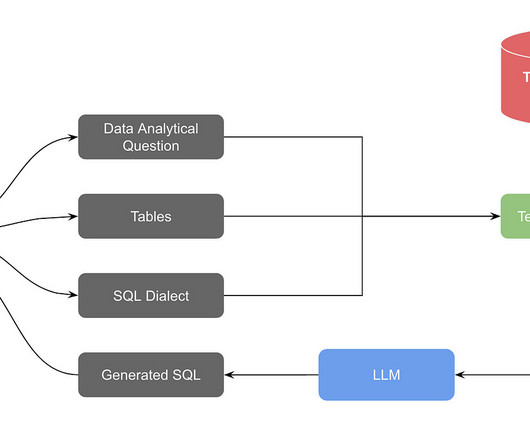
Now, back to the original programming: Articles Pinterest wrote a blog post on generating SQL queries from text. The initial version of the Text-to-SQL solution relied on an LLM as the core component. This information, along with the specific SQL dialect used at Pinterest, would then be compiled into a prompt and fed into the LLM.
AWS Machine Learning Blog
DECEMBER 5, 2023
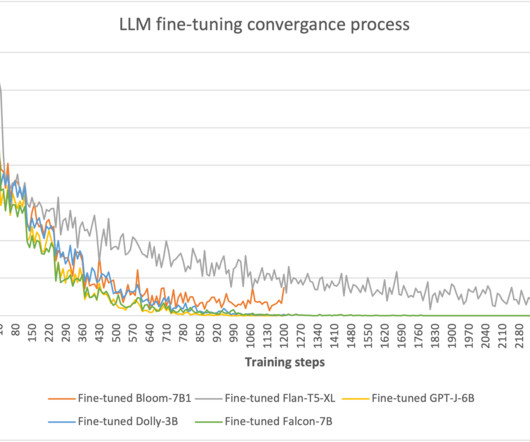
New and powerful large language models (LLMs) are changing businesses rapidly, improving efficiency and effectiveness for a variety of enterprise use cases. Speed is of the essence, and adoption of LLM technologies can make or break a business’s competitive advantage.

Expert insights. Personalized for you.




















Let's personalize your content