

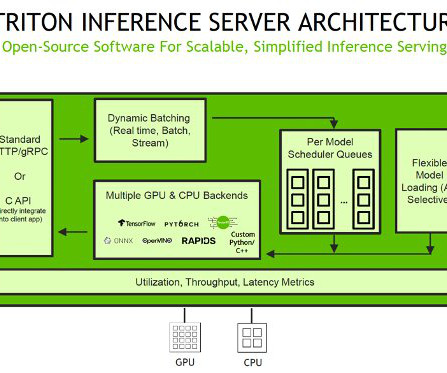
Host ML models on Amazon SageMaker using Triton: TensorRT models
AWS Machine Learning Blog
MAY 8, 2023
With kernel auto-tuning, the engine selects the best algorithm for the target GPU, maximizing hardware utilization. This engine is then loaded into Triton Inference Server and used to perform inference on incoming requests. Load the TensorRT engine in Triton Inference Server. Generating serialized engines from models.






Let's personalize your content