Streaming in Production: Collected Best Practices, Part 2
databricks
JANUARY 9, 2023
In our two-part blog series titled "Streaming in Production: Collected Best Practices," this is the second article. Here we discuss the "After Deployment".

 streaming-production-collected-best-practices Blog Related Topics
streaming-production-collected-best-practices Blog Related Topics 
databricks
JANUARY 9, 2023
In our two-part blog series titled "Streaming in Production: Collected Best Practices," this is the second article. Here we discuss the "After Deployment".

databricks
DECEMBER 12, 2022
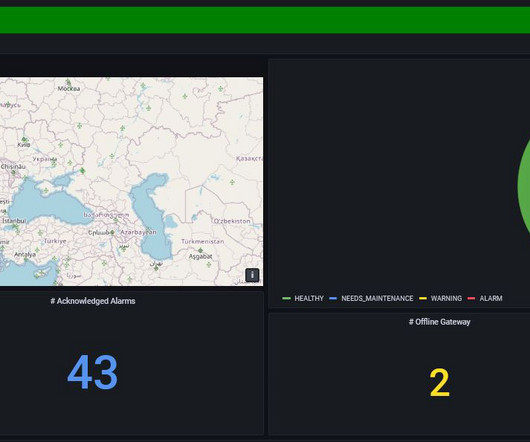
Releasing any data pipeline or application into a production state requires planning, testing, monitoring, and maintenance. Streaming pipelines are no different in this.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
IBM Journey to AI blog
APRIL 21, 2023
During scoping and implementation: We know that product innovations that deliver enterprise-wide value can be capital intensive. Continuously: Leaders that want their product innovations to be sustainable must align with their finance peers.
AWS Machine Learning Blog
MAY 9, 2024
According to a McKinsey study , across the financial services industry (FSI), generative AI is projected to deliver over $400 billion (5%) of industry revenue in productivity benefits. At Amazon, we believe innovation (rethink and reinvent) drives improved customer experiences and efficient processes, leading to increased productivity.

IBM Journey to AI blog
DECEMBER 7, 2023
They are seamlessly integrated with cloud-based data warehouses, facilitating the collection, storage and analysis of data from various sources. Identifying best practices and benefits In the realm of OLAP, AI’s role is increasingly important.
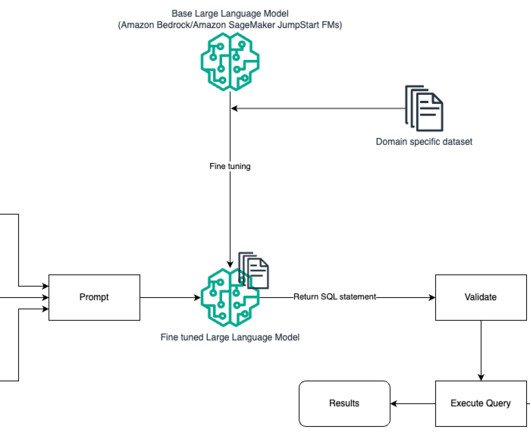
AWS Machine Learning Blog
JANUARY 4, 2024
In this post, we provide an introduction to text to SQL (Text2SQL) and explore use cases, challenges, design patterns, and best practices. However, it’s best to initially attempt prompt engineering without fine-tuning, because this allows rapid iteration without data collection. This avoids reprocessing repeated queries.
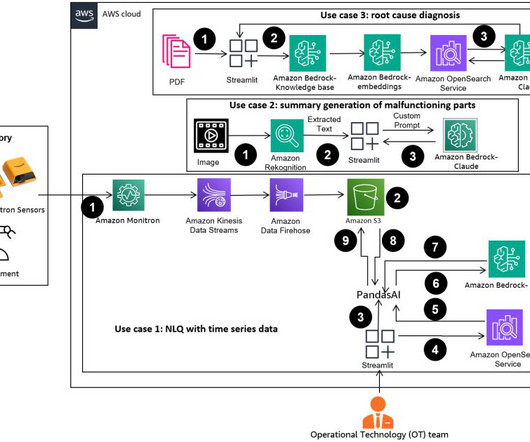
AWS Machine Learning Blog
MARCH 19, 2024
In the evolving landscape of manufacturing, the transformative power of AI and machine learning (ML) is evident, driving a digital revolution that streamlines operations and boosts productivity. The Streamlit app collects the response via PandasAI, and provides the output to users. Open the SageMaker notebook instance in JupyterLab.

Expert insights. Personalized for you.






























Let's personalize your content