

High-quality human feedback for your generative AI applications from Amazon SageMaker Ground Truth Plus
AWS Machine Learning Blog
MAY 30, 2023
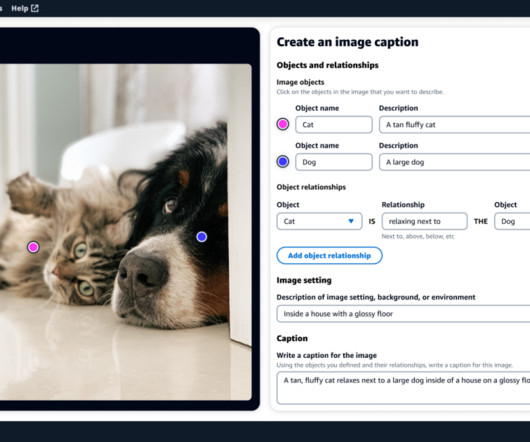
For multi-modal models, such as text-to-image or text-to-video models, the models may output content unrelated to the prompt. Even if models are fine-tuned to perform specific tasks, they may not be aligned with human preferences with respect to the meaning, style, or substance of their output content.






Let's personalize your content