

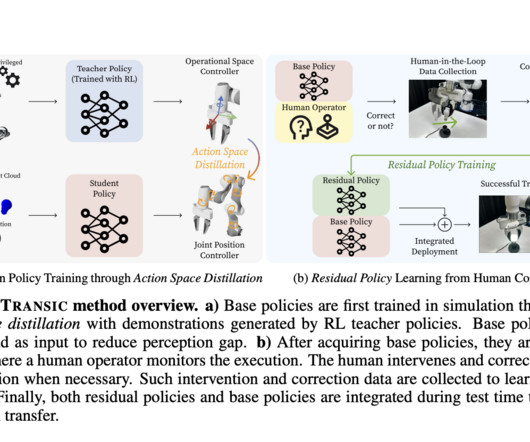
Researchers at Stanford Propose TRANSIC: A Human-in-the-Loop Method to Handle the Sim-to-Real Transfer of Policies for Contact-Rich Manipulation Tasks
Marktechpost
MAY 22, 2024
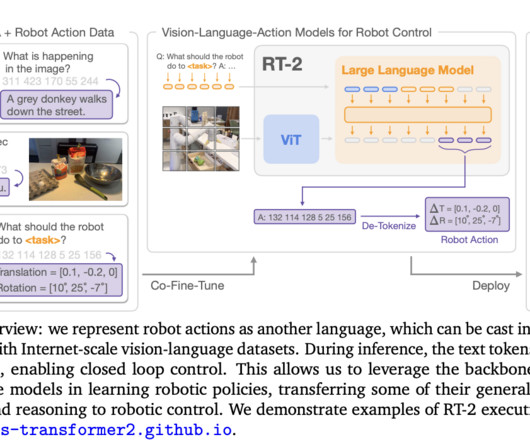
Learning in simulation and applying the learned policy to the real world is a potential approach to enable generalist robots, and solve complex decision-making tasks. So, it becomes important to smoothly transfer and deploy robot control policies into real-world hardware using reinforcement learning (RL).




































Let's personalize your content