

7 Critical Model Training Errors: What They Mean & How to Fix Them
Viso.ai
JANUARY 30, 2024
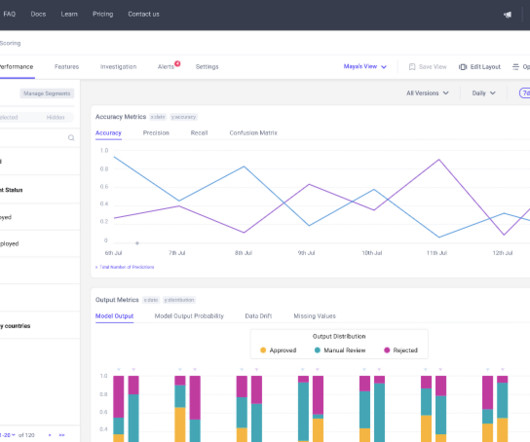
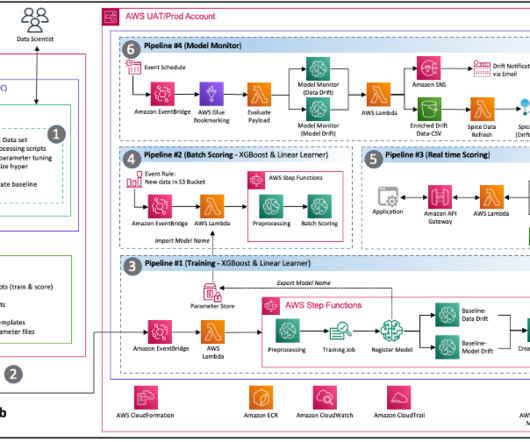
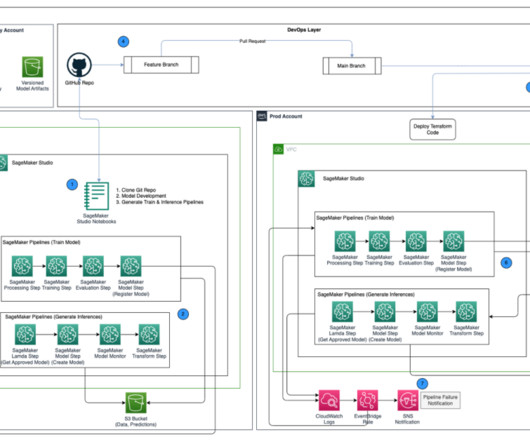
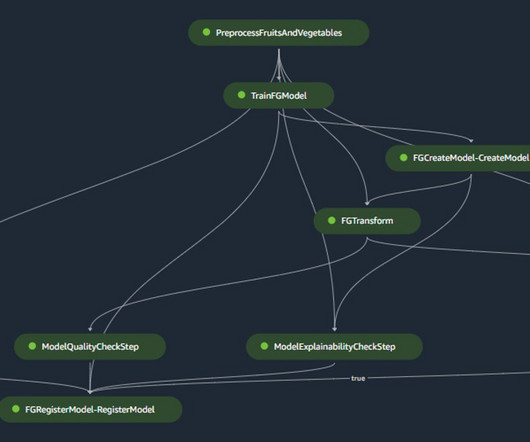
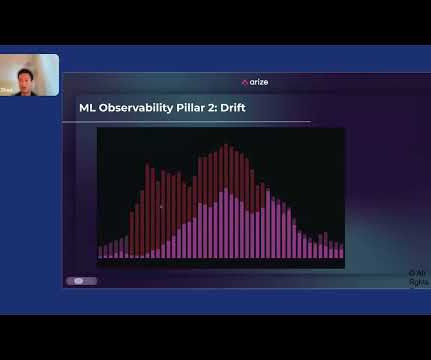
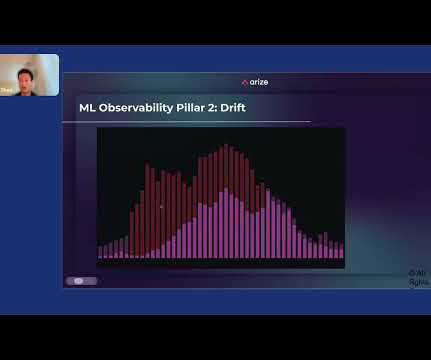
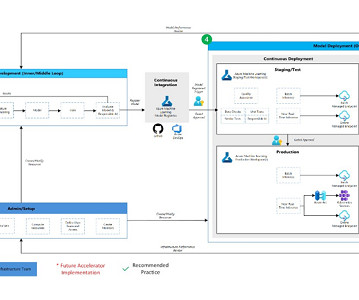
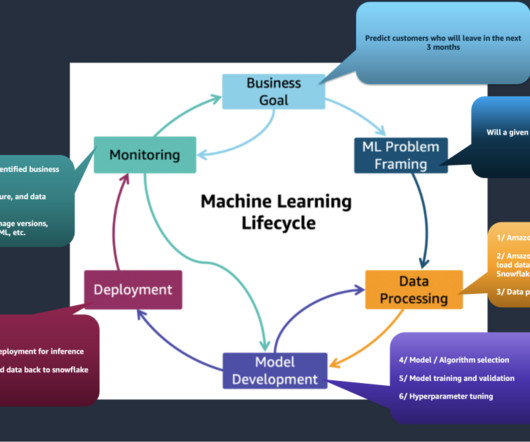
” We will cover the most important model training errors, such as: Overfitting and Underfitting Data Imbalance Data Leakage Outliers and Minima Data and Labeling Problems Data Drift Lack of Model Experimentation About us: At viso.ai, we offer the Viso Suite, the first end-to-end computer vision platform.
















Let's personalize your content