

NLP News Cypher | 07.26.20
Towards AI
JULY 21, 2023
Photo by Will Truettner on Unsplash NATURAL LANGUAGE PROCESSING (NLP) WEEKLY NEWSLETTER NLP News Cypher | 07.26.20 GitHub: Tencent/TurboTransformers Make transformers serving fast by adding a turbo to your inference engine!Transformer Primus The Liber Primus is unsolved to this day.
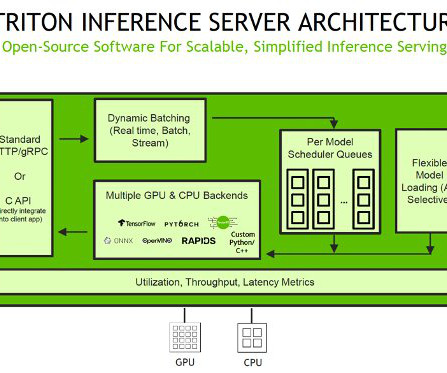
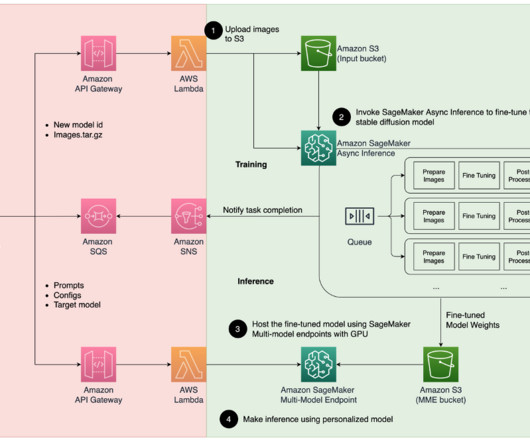






Let's personalize your content