

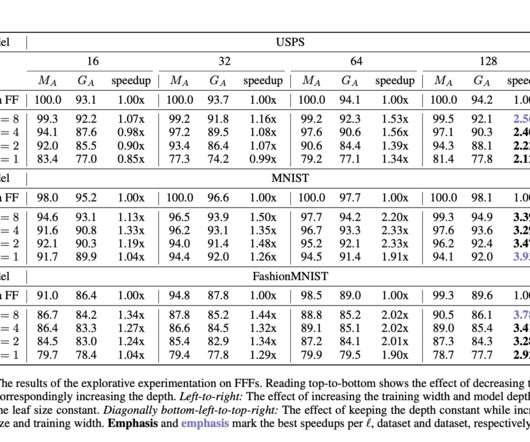
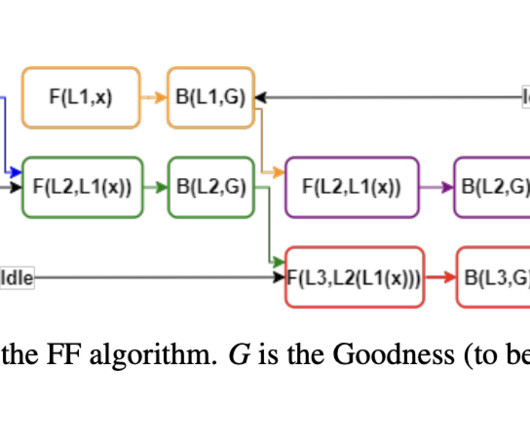
ETH Zurich Researchers Introduce the Fast Feedforward (FFF) Architecture: A Peer of the Feedforward (FF) Architecture that Accesses Blocks of its Neurons in Logarithmic Time
Marktechpost
SEPTEMBER 26, 2023
The post ETH Zurich Researchers Introduce the Fast Feedforward (FFF) Architecture: A Peer of the Feedforward (FF) Architecture that Accesses Blocks of its Neurons in Logarithmic Time appeared first on MarkTechPost. If you like our work, you will love our newsletter.







Let's personalize your content