

Machine learning with decentralized training data using federated learning on Amazon SageMaker
AWS Machine Learning Blog
AUGUST 22, 2023
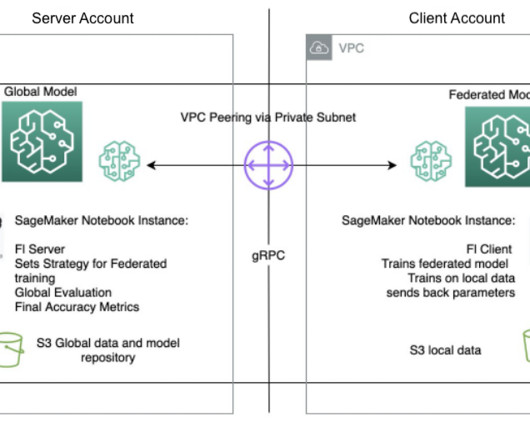
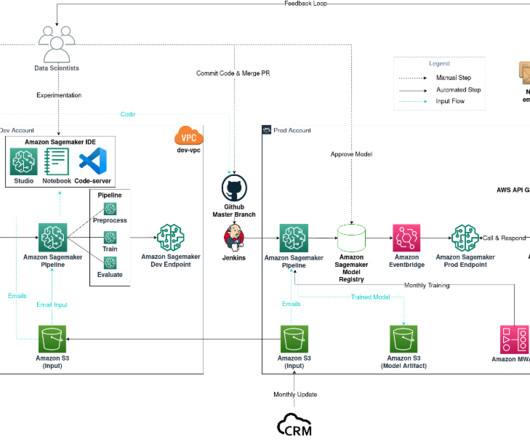
In this post, we discuss how to implement federated learning on Amazon SageMaker to run ML with decentralized training data. In this post, we discuss how to implement federated learning on Amazon SageMaker to run ML with decentralized training data. What is federated learning? Each account or Region has its own training instances.









Let's personalize your content