

Accelerate NLP inference with ONNX Runtime on AWS Graviton processors
AWS Machine Learning Blog
MAY 15, 2024
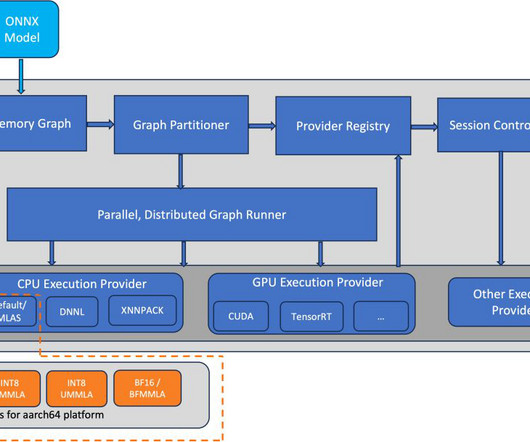
The first figure illustrates the ONNX software stack, highlighting (in orange) the components optimized for inference performance improvement on the AWS Graviton3 platform. You can see that for the BERT, RoBERTa, and GPT2 models, the throughput improvement is up to 65%. for the same fp32 model inference. for the same model inference.











Let's personalize your content