

ScalaHosting Review: The Best High-performance Host for Your Website?
Unite.AI
MAY 6, 2024
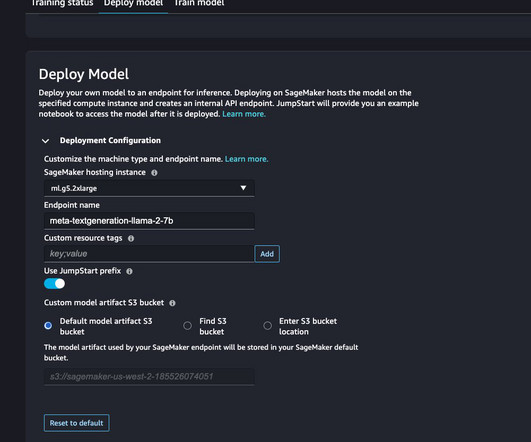
Check out their pricing plans below: ScalaHosting’s shared hosting plans Mini Space offered – 10 GB fixed NVMe SSD Bandwidth – Unmetered bandwidth Number of websites – 1 website allowed Price – $2.95/month month I recommend ScalaHosting’s Entry Cloud plan because it gives you the most value for your money.














Let's personalize your content