

ChatGPT Meets Its Match: The Rise of Anthropic Claude Language Model
Unite.AI
JANUARY 3, 2024
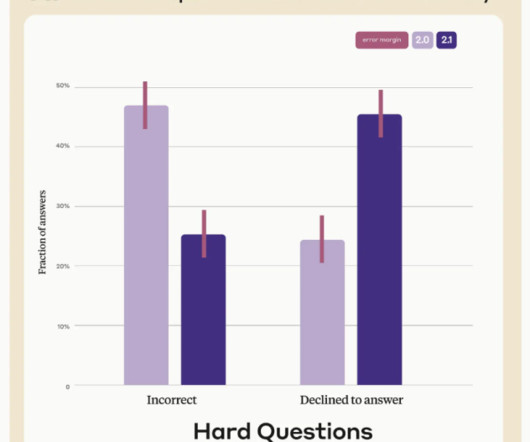
Overview of Claude Claude powered by Claude 2 & Claude 2.1 One major feature is the expansion of its context window to 200,000 tokens, enabling approximately 150,000 words or over 500 pages of text. Access and Pricing Claude 2.1 Claude stands out with its advanced technical features. to handle much larger bodies of data.




















Let's personalize your content