

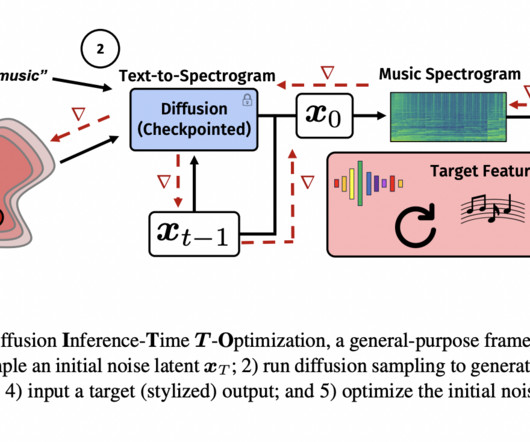
This AI Paper from Adobe and UCSD Presents DITTO: A General-Purpose AI Framework for Controlling Pre-Trained Text-to-Music Diffusion Models at Inference-Time via Optimizing Initial Noise Latents
Marktechpost
JANUARY 26, 2024
A key challenge in text-to-music generation using diffusion models is controlling pre-trained text-to-music diffusion models at inference time. While effective, these models can only sometimes produce fine-grained and stylized musical outputs. Research in the field of computer-generated music has made significant progress.
















Let's personalize your content