

This AI Paper Introduces the Open-Vocabulary SAM: A SAM-Inspired Model Designed for Simultaneous Interactive Segmentation and Recognition
Marktechpost
JANUARY 14, 2024
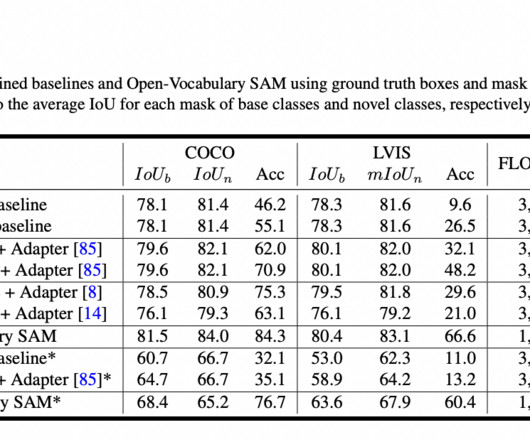
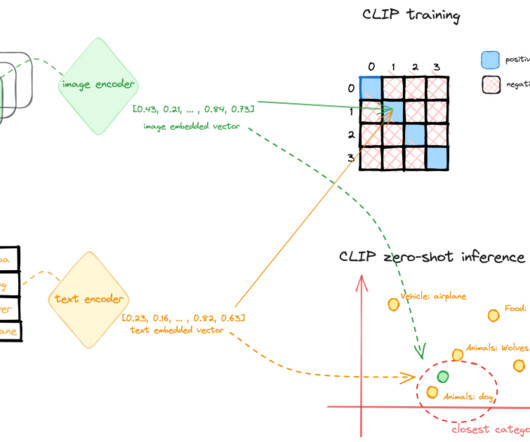
Combining CLIP and the Segment Anything Model (SAM) is a groundbreaking Vision Foundation Models (VFMs) approach. SAM performs superior segmentation tasks across diverse domains, while CLIP is renowned for its exceptional zero-shot recognition capabilities. SAM, for instance, cannot recognize the segments it identifies.





















Let's personalize your content