


AI Learns from AI: The Emergence of Social Learning Among Large Language Models
Unite.AI
MARCH 22, 2024
These LLMs, designed to process and generate human-like text, learn from an extensive array of texts from the internet, ranging from books to websites. This learning process allows them to capture the essence of human language making them general purpose problem solvers. What's Social Learning? Social learning isn't a new idea.
























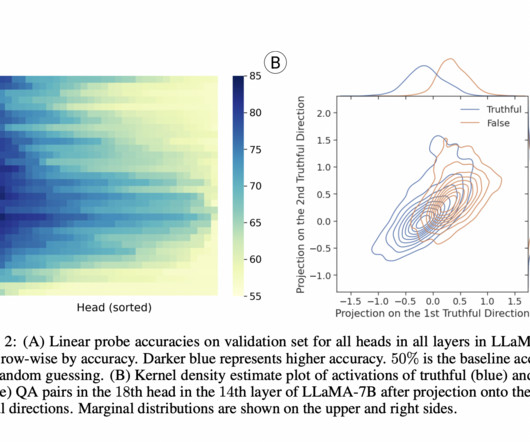
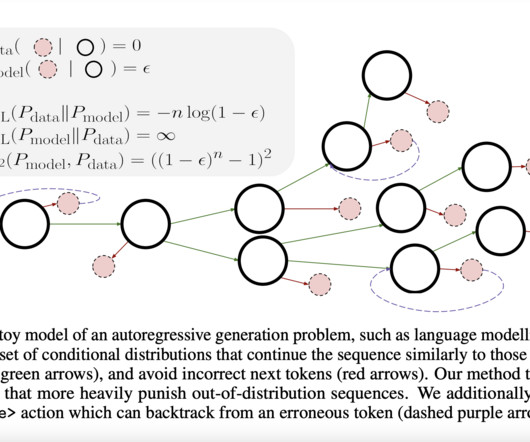





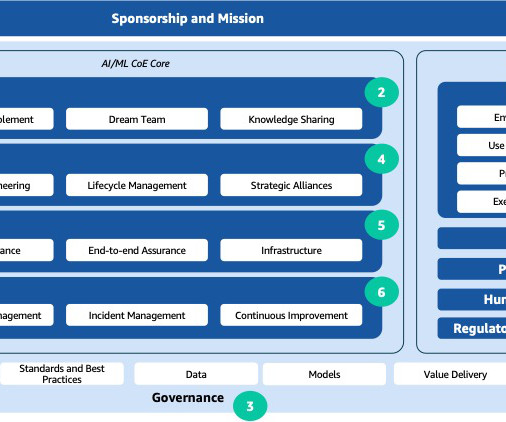

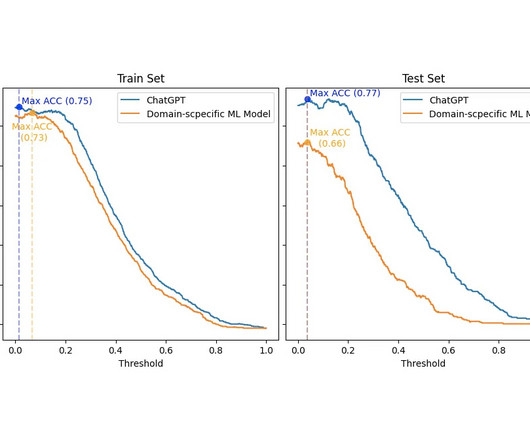






Let's personalize your content