'Big Boss' Workstation Debuts With 7 RTX 4090 GPUs, $31k Price Tag
Extreme Tech
AUGUST 22, 2023
This European mega machine will easily shred any workload.

 tag gpus
tag gpus 
Extreme Tech
AUGUST 22, 2023
This European mega machine will easily shred any workload.
AWS Machine Learning Blog
APRIL 19, 2024
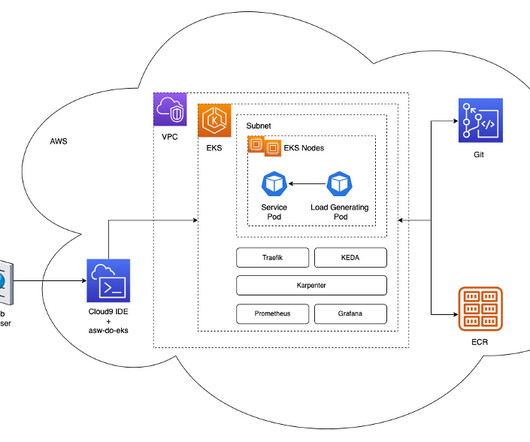
Initially, our model fine-tuning took hours of CPU time, so a framework for scaling model fine-tuning on GPUs was imperative. Our deep learning models have non-trivial requirements: they are gigabytes in size, are numerous and heterogeneous, and require GPUs for fast inference and fine-tuning. Karpenter adds g4dn.metal and g4dn.12xlarge
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
AWS Machine Learning Blog
NOVEMBER 20, 2023
KT’s AI Food Tag is an AI-based dietary management solution that identifies the type and nutritional content of food in photos using a computer vision model. The AI Food Tag can help patients with chronic diseases such as diabetes manage their diets. In this post, we describe KT’s model development journey and success using SageMaker.

Marktechpost
MARCH 30, 2024
The Core of Pollen-Vision At the heart of Pollen-Vision are several pivotal models, each selected for its zero-shot capability and real-time performance on consumer-grade GPUs. Core models within Pollen-Vision, such as OWL-VIT, Mobile Sam, and RAM, offer diverse capabilities from object localization to image segmentation and tagging.

NVIDIA
SEPTEMBER 21, 2023
The NVIDIA Studio laptop lineup is expanding with the new Microsoft Surface Laptop Studio 2, powered by GeForce RTX 4060 , GeForce RTX 4050 or NVIDIA RTX 2000 Ada Generation Laptop GPUs, providing powerful performance and versatility for creators. faster on GeForce RTX and NVIDIA RTX GPUs compared to Macs.

NVIDIA
JULY 6, 2023
link] In addition, get a glimpse of two cloud-based AI apps, Wondershare Filmora and Trimble SketchUp Go, powered by NVIDIA RTX GPUs, and learn how they can elevate and automate content creation. Those who own NVIDIA or GeForce RTX GPUs can take advantage of Tensor Cores that utilize AI to accelerate over 100 apps.

NVIDIA
JANUARY 16, 2024
Daz features an AI denoiser for high-performance interactive rendering that can also be accelerated by RTX GPUs. Here, Brellias’ RTX GPU accelerated the color grading, video editing and color scoping processes, dramatically speeding his creative workflow.

Expert insights. Personalized for you.


























Let's personalize your content