


LLMs cannot find any more data, what are they going to do now?
Bitext
SEPTEMBER 22, 2023
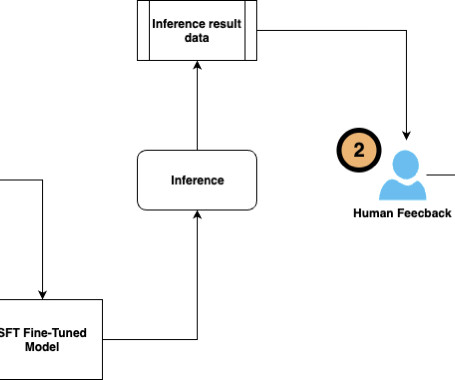
To address this challenge, we have produced “Hybrid Datasets” (like in “hybrid cars”). We call them hybrid because they are a combination of manual and synthetic data, created with a methodology that combines NLG technology with curation by linguists and vertical experts. What are the advantages of “Hybrid Datasets”?






























Let's personalize your content