

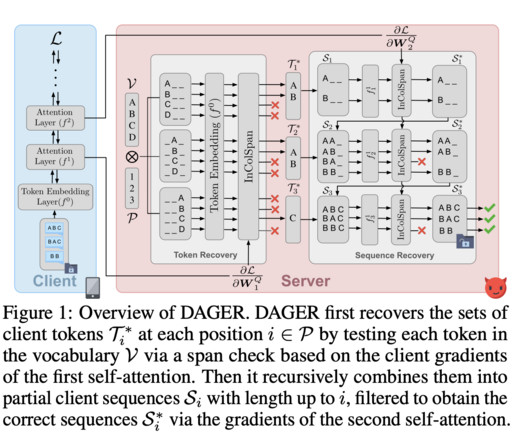
Overcoming Gradient Inversion Challenges in Federated Learning: The DAGER Algorithm for Exact Text Reconstruction
Marktechpost
MAY 28, 2024
This challenges LLMs in sensitive fields like law and medicine, where privacy is crucial. Tested on models like BERT, GPT-2, and Llama2-7B, and datasets such as CoLA, SST-2, Rotten Tomatoes, and ECHR, DAGER consistently outperformed TAG and LAMP. Researchers from INSAIT, Sofia University, ETH Zurich, and LogicStar.ai















Let's personalize your content