

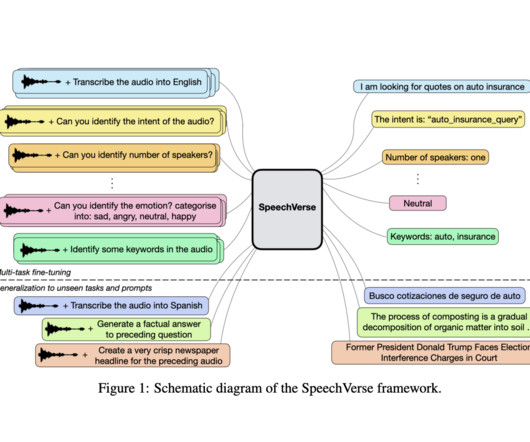
SpeechVerse: A Multimodal AI Framework that Enables LLMs to Follow Natural Language Instructions for Performing Diverse Speech-Processing Tasks
Marktechpost
MAY 17, 2024
Particularly, instruction-following multimodal audio-language models are gaining traction due to their ability to generalize across tasks. However, multimodal large language models integrating audio have garnered less attention. Models like T5 and SpeechNet employ this approach for text and speech tasks, achieving significant results.


























Let's personalize your content