
ACL 2021 Highlights
Sebastian Ruder
AUGUST 15, 2021
ACL 2021 took place virtually from 1–6 August 2021. These models are essentially all variants of the same Transformer architecture.
Sebastian Ruder
AUGUST 15, 2021
ACL 2021 took place virtually from 1–6 August 2021. These models are essentially all variants of the same Transformer architecture.

AWS Machine Learning Blog
FEBRUARY 6, 2024
In 2021, the pharmaceutical industry generated $550 billion in US revenue. Transformers, BERT, and GPT The transformer architecture is a neural network architecture that is used for natural language processing (NLP) tasks. The other data challenge for healthcare customers are HIPAA compliance requirements.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Topbots
APRIL 11, 2023
We’ll start with a seminal BERT model from 2018 and finish with this year’s latest breakthroughs like LLaMA by Meta AI and GPT-4 by OpenAI. BERT by Google Summary In 2018, the Google AI team introduced a new cutting-edge model for Natural Language Processing (NLP) – BERT , or B idirectional E ncoder R epresentations from T ransformers.
Mlearning.ai
MARCH 2, 2023
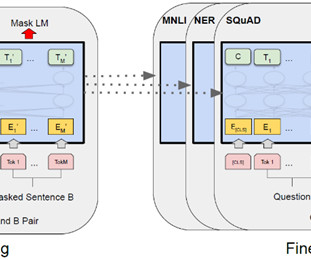
Pre-training of Deep Bidirectional Transformers for Language Understanding BERT is a language model that can be fine-tuned for various NLP tasks and at the time of publication achieved several state-of-the-art results. Finally, the impact of the paper and applications of BERT are evaluated from today’s perspective. 1 Architecture III.2
Mlearning.ai
OCTOBER 2, 2023
Famous models like BERT and others, begin their journey with initial training on massive datasets encompassing vast swaths of internet text. ArXiv , 2021, /abs/2106.10199. In the next blog we will use Low-Rank adapters to efficiently fine tune a large model. It also serves as a powerful lever for refining the abilities of LLMs.
Sebastian Ruder
JANUARY 24, 2022
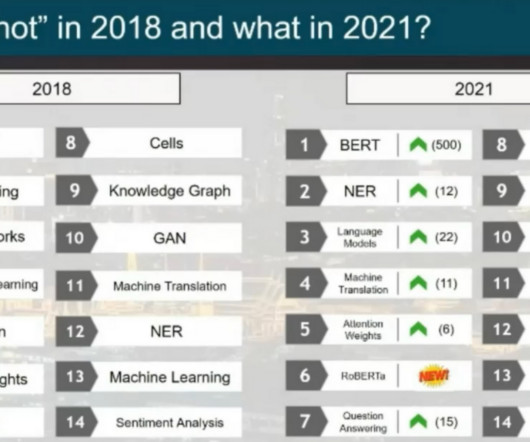
2021) 2021 saw many exciting advances in machine learning (ML) and natural language processing (NLP). 2021 saw the continuation of the development of ever larger pre-trained models. 6] such as W2v-BERT [7] as well as more powerful multilingual models such as XLS-R [8]. Credit for the title image: Liu et al.
Bugra Akyildiz
DECEMBER 18, 2022
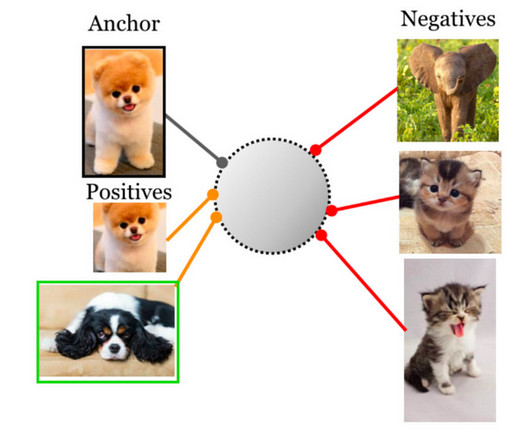
Before going further, a new announcement for embeddings also came from OpenAI: openai.com/blog/new-and-i… nnIt is cross-modal, and it is 1/500th of the price of the old embedding model DaVinci. ","username":"bugraa","name":"Bugra Dragon can be used as a drop-in replacement for BERT.

Expert insights. Personalized for you.














Let's personalize your content