

Can LLM-based eval replace human evaluation?
Ehud Reiter
JUNE 10, 2024
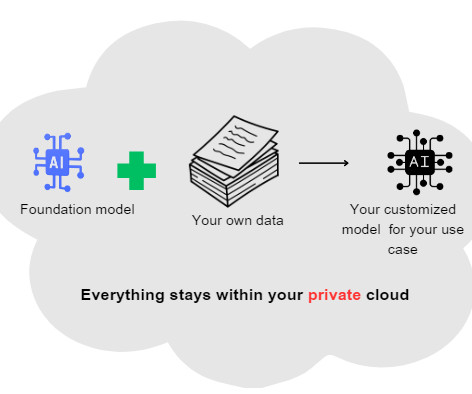
I’ve had several chats over the past month about whether LLM-based evaluation can replace human evaluation. Of course the LLM evaluation must be done well, for example LLMs should not be asked to evaluate their own output (ie, do not ask GPT4 to evaluate text produced by GPT4).



































Let's personalize your content