

The power of remote engine execution for ETL/ELT data pipelines
IBM Journey to AI blog
MAY 15, 2024
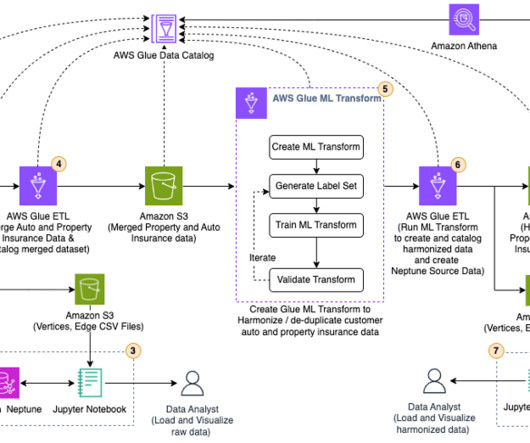
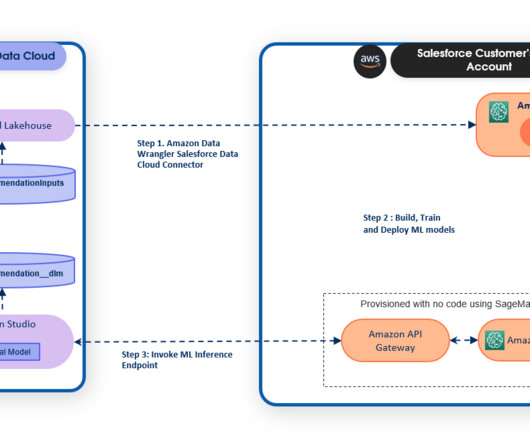
Unified, governed data can also be put to use for various analytical, operational and decision-making purposes. This process is known as data integration, one of the key components to a strong data fabric. The remote execution engine is a fantastic technical development which takes data integration to the next level.

















Let's personalize your content