
QoQ and QServe: A New Frontier in Model Quantization Transforming Large Language Model Deployment
Marktechpost
MAY 12, 2024
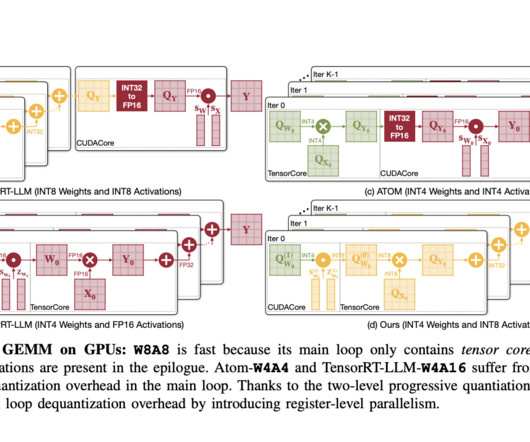
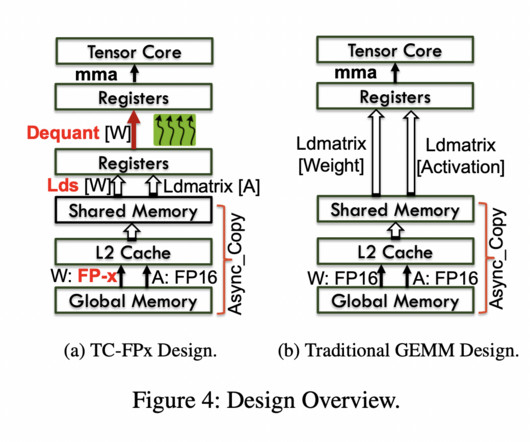
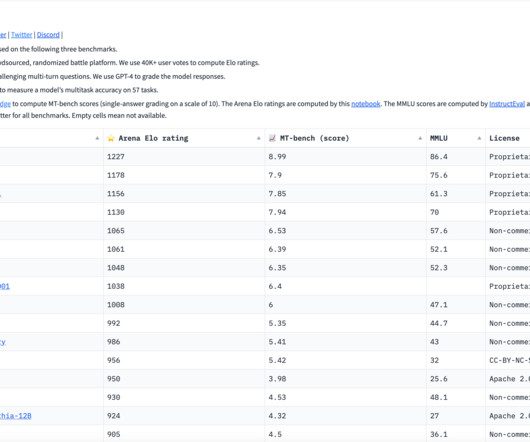
Quantization, a method integral to computational linguistics, is essential for managing the vast computational demands of deploying large language models (LLMs). It simplifies data, thereby facilitating quicker computations and more efficient model performance. Check out the Paper.



















Let's personalize your content