
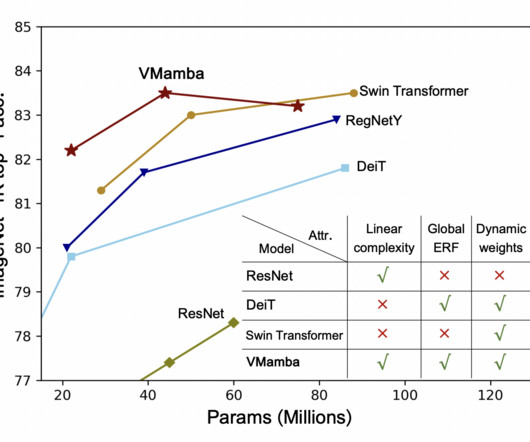
Meet VMamba: An Alternative to Convolutional Neural Networks CNNs and Vision Transformers for Enhanced Computational Efficiency
Marktechpost
JANUARY 23, 2024
There are two major challenges in visual representation learning: the computational inefficiency of Vision Transformers (ViTs) and the limited capacity of Convolutional Neural Networks (CNNs) to capture global contextual information. A team of researchers at UCAS, in collaboration with Huawei Inc.


























Let's personalize your content