
How Axfood enables accelerated machine learning throughout the organization using Amazon SageMaker
AWS Machine Learning Blog
FEBRUARY 27, 2024
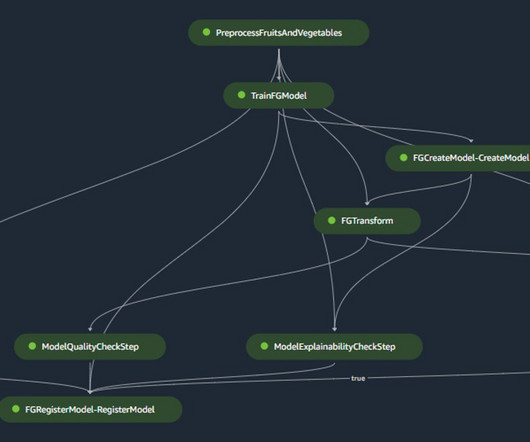
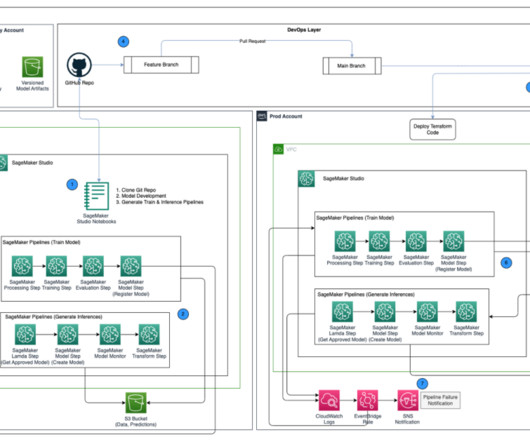
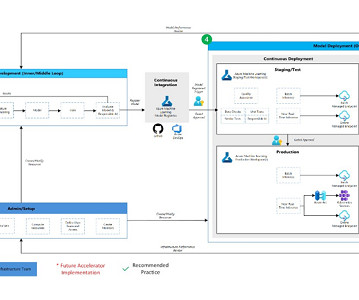
The SageMaker project template includes seed code corresponding to each step of the build and deploy pipelines (we discuss these steps in more detail later in this post) as well as the pipeline definition—the recipe for how the steps should be run. Pavel Maslov is a Senior DevOps and ML engineer in the Analytic Platforms team.











Let's personalize your content