
How Axfood enables accelerated machine learning throughout the organization using Amazon SageMaker
AWS Machine Learning Blog
FEBRUARY 27, 2024
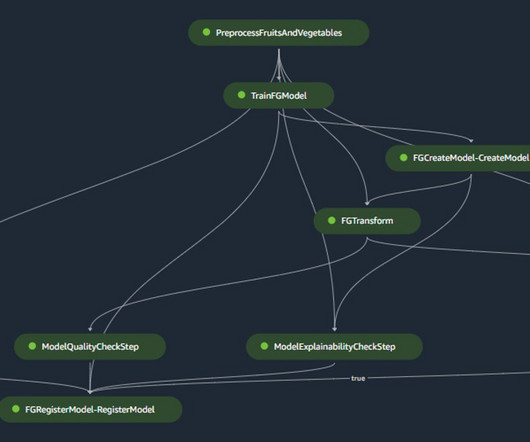
However, there are many clear benefits of modernizing our ML platform and moving to Amazon SageMaker Studio and Amazon SageMaker Pipelines. Monitoring – Continuous surveillance completes checks for drifts related to data quality, model quality, and feature attribution. Workflow B corresponds to model quality drift checks.















Let's personalize your content