
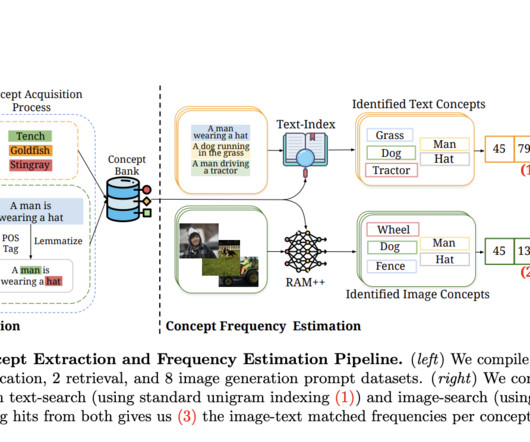
The “Zero-Shot” Mirage: How Data Scarcity Limits Multimodal AI
Marktechpost
APRIL 10, 2024
Don’t Forget to join our 40k+ ML SubReddit The post The “Zero-Shot” Mirage: How Data Scarcity Limits Multimodal AI appeared first on MarkTechPost. Join our Telegram Channel , Discord Channel , and LinkedIn Gr oup. If you like our work, you will love our newsletter.
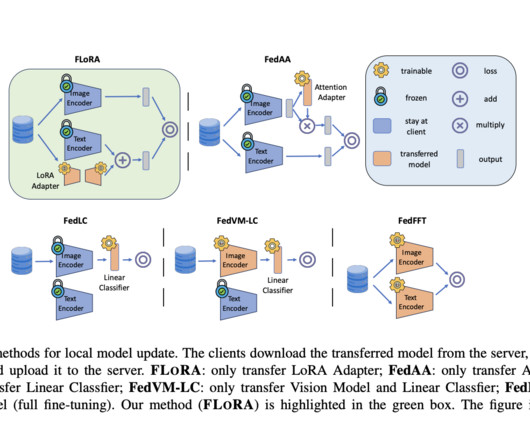


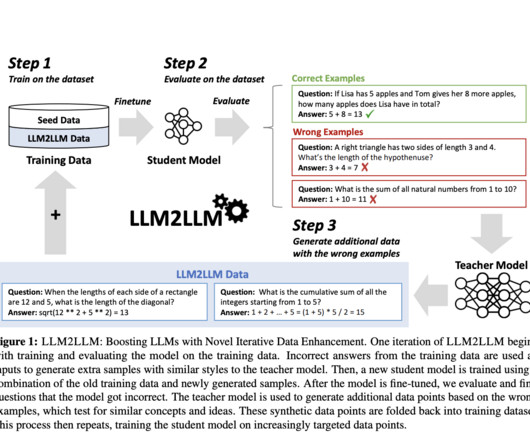

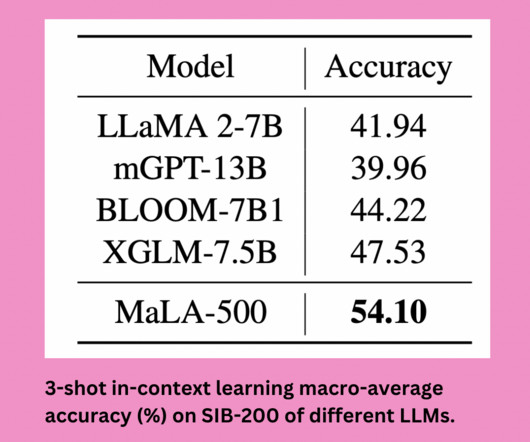
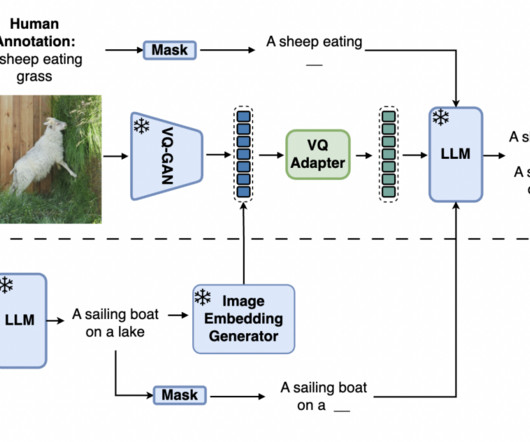


















Let's personalize your content