


A Deep Dive into Retrieval-Augmented Generation in LLM
Unite.AI
OCTOBER 2, 2023
Especially when the task at hand is knowledge-intensive, these models can lag behind more specialized architectures. OpenAI's ChatGPT Gets a Browsing Upgrade OpenAI's recent announcement about ChatGPT's browsing capability is a significant leap in the direction of Retrieval-Augmented Generation (RAG).
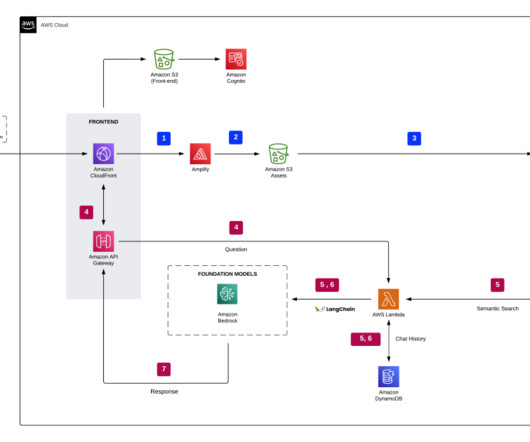
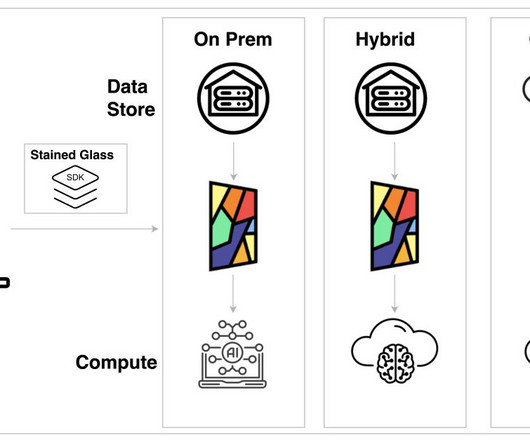

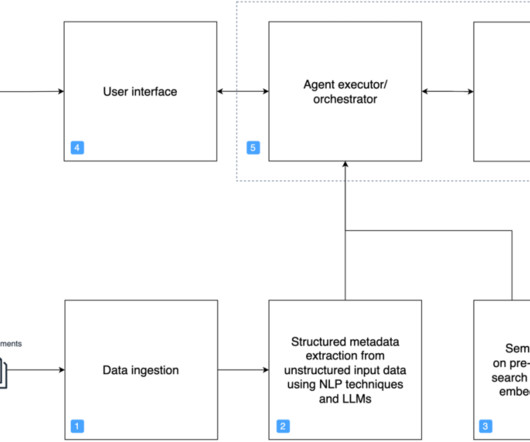
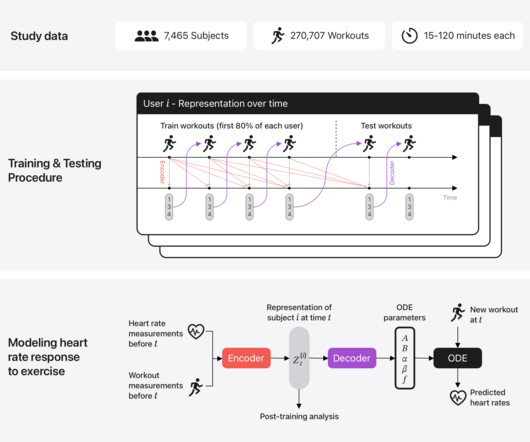










Let's personalize your content